Learn how to track LLM brand mentions across ChatGPT, Claude, and Perplexity. A 7-step system with prompts, tools, and metrics. Updated April 2026.
Your brand is showing up in AI answers right now. You just do not know where, how often, or what the model is saying about you. That invisibility is the most expensive problem in modern SEO.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
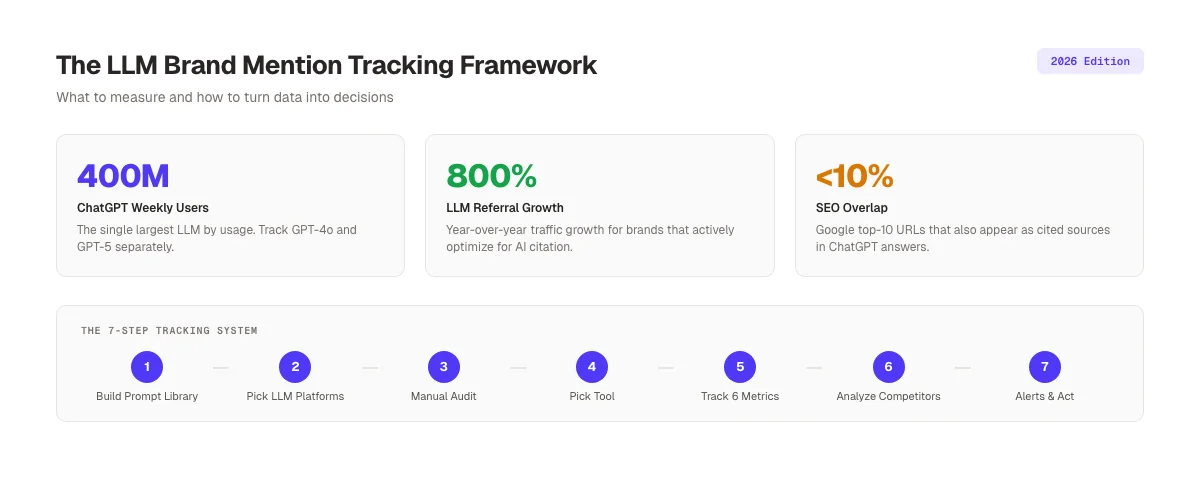
ChatGPT has 400 million weekly active users. Perplexity handles 20 million daily queries. Claude, Gemini, and Copilot round out the rest. These models recommend products, compare vendors, and shape buying decisions every minute of every day. If a competitor appears in 60% of category answers and you appear in 8%, you are losing pipeline you will never see in Google Analytics.
This guide shows you how to track LLM brand mentions across every major AI platform. You will build a prompt library, run a baseline audit, pick a monitoring tool, and set up alerts that catch visibility drops before they cost you revenue.
We publish 3,500+ blog posts across 70+ industries with SEO scoring on every article before publish. LLM brand mention tracking is part of every reporting cycle we run for customers.
Here is what you will learn:
- How to build a 30-prompt tracking library for your brand
- Which AI platforms to monitor (and which to skip)
- How to run a baseline audit in under 2 hours
- The 6 metrics that define LLM brand visibility
- How to measure share of voice against competitors
- How to set alerts for ranking changes in AI answers
- A monthly monitoring routine you can automate
What You Will Need
Time required: 2 to 3 hours for initial setup. 30 to 60 minutes per month ongoing.
Difficulty: Beginner to Intermediate
What you will need:
- Access to ChatGPT, Claude, Perplexity, and Gemini (free plans work for the audit)
- A spreadsheet (Google Sheets or Airtable)
- An incognito browser window
- Optional: A dedicated LLM monitoring tool with a free trial
- A list of 3 to 5 direct competitors
- 90 minutes of focused work
Why LLM Brand Mention Tracking Matters in 2026
Traditional SEO tools track rankings. They do not track mentions inside generated answers. That gap is the blind spot killing forecasting accuracy in most marketing teams.
Gartner projects organic search traffic to commercial sites will drop 25% by 2026 as buyers shift discovery to ChatGPT, Perplexity, Gemini, and Copilot. Yet fewer than 12% of marketing teams have a documented AI visibility strategy. The ones that do are building a flywheel the rest cannot see.
LLM referral traffic grew 800% year-over-year for sites that actively optimize for AI citation. Fewer than 10% of sources cited in ChatGPT, Gemini, and Copilot also rank in the top 10 Google organic results for the same query. That means classical SEO does not translate automatically into AI visibility.
The difference between a brand mentioned 3 times and one mentioned 30 times per 100 category prompts is the difference between a footnote and a category leader. You cannot close that gap without tracking first. For a full primer on the metric itself, read our guide on LLM visibility.
Step 1: Build Your Prompt Tracking Library
Start with prompts, not tools. Every monitoring system depends on the list of questions you feed it. A bad prompt list produces a vanity dashboard. A good one exposes exactly how AI models position your brand.
Build 30 prompts across 5 categories. That is enough volume to spot patterns and small enough to audit manually once per quarter.
The 5 prompt categories:
| Category | Example Prompt | What It Reveals |
|---|---|---|
| Direct brand query | "What is [Brand]?" | Does the model know you exist and describe you correctly |
| Category discovery | "Best [category] tools for small business" | Whether you appear in unaided consideration sets |
| Comparison | "[Brand] vs [Competitor]" | Your positioning against specific rivals |
| Problem solution | "How do I [solve problem your product solves]" | Whether you surface as a recommended fix |
| Use case | "Best tool for [specific use case]" | Long-tail visibility where buyers live |
Write 6 prompts per category. Mix in buyer language, not marketing language. Pull phrasing from Reddit threads, G2 reviews, and actual sales call transcripts. Buyers say "cheap SEO tool," not "affordable SEO platform."
Specifically:
- Include 2 direct brand prompts ("What is [Brand]," "Is [Brand] legit")
- Include 2 misspellings of your brand name
- Include 10 category prompts with modifiers (best, top, cheapest, for agencies)
- Include 6 comparison prompts pitting you against named competitors
- Include 6 problem-solution prompts in buyer language
- Include 4 use-case prompts with industry modifiers
Why this step matters: The wrong prompts produce the wrong picture. If you only track "What is [Brand]," you will always see 100% coverage and miss that you rank zero for the 50 category prompts buyers actually use.
Pro tip: Run your prompt list past a product marketer or a sales rep. They will catch the queries buyers actually ask that you will never think of from inside the company.
Step 2: Pick the Right LLM Platforms to Monitor
Not every model deserves equal attention. The goal is coverage of the platforms your buyers actually use, not exhaustive monitoring of every model in existence.
![]()
Track these five at minimum:
ChatGPT , 400M weekly active users. The single largest LLM by usage. Test GPT-4o and GPT-5 separately because they return different answers.
Claude , 30M weekly active users. Heavily used by knowledge workers, developers, and agencies. Often cited by professional buyers doing vendor research.
Perplexity , 20M daily queries. Source-cited answers mean your URLs can appear directly. The platform with the most measurable visibility for publishers.
Google Gemini. Bundled with Workspace and powering Google AI Overviews. If you sell to Google Workspace shops, this is non-negotiable. Learn more about Google AI Overviews.
Microsoft Copilot. Inherits OpenAI models and adds Bing sourcing. High weight for enterprise buyers using Microsoft 365.
Add Grok and Meta AI only if your audience clusters on X or Instagram. Most B2B and local service brands can skip them.
Test each platform twice: once with web search enabled, once disabled. This separates training data gaps from content gaps. If your brand appears with web search on but not off, the model does not know you from its training data. That is a brand authority problem, not an SEO problem. The fix is more mentions on the sites AI models crawl and cite. Reddit and Wikipedia both appear disproportionately in AI answers, so both belong in your earned media plan.
Why this step matters: Skipping a platform your buyers use is the same as skipping a search engine. Enterprise buyers using Copilot will never see your ChatGPT ranking, and vice versa.
Step 3: Run Your Baseline Manual Audit
Before you pay for a tool, audit manually. A baseline audit teaches you what to measure, reveals the prompts where you already win, and surfaces the ones where you are invisible.
Open an incognito window. Log out of every AI account. This removes personalization and conversation memory that skew results toward queries you have already run.
Create a spreadsheet with these columns:
| Column | Purpose |
|---|---|
| Date | When the query ran |
| Platform | ChatGPT, Claude, Perplexity, Gemini, Copilot |
| Model version | GPT-5, Claude Opus 4.7, Sonar Pro |
| Prompt | Exact wording used |
| Web search | On or Off |
| Mentioned | Yes or No |
| Position | 1st, 2nd, 3rd, or buried |
| Sentiment | Positive, Neutral, Negative |
| Accuracy | Correct, Partial, Wrong |
| Competitors cited | Comma-separated list |
| Sources cited | URLs the model linked to |
| Notes | Anomalies, misinformation, wins |
Run every prompt once on every platform. Paste the full response into a "raw response" column. Mark brand mentions in bold so you can eyeball patterns later.
Expect 30 prompts times 5 platforms to take 2 hours. Run each prompt twice on ChatGPT and Claude because responses vary between queries due to temperature. Average the results.
Specifically, document:
- ✓ Did the model mention your brand at all
- ✓ Was the description accurate (pricing, features, positioning)
- ✓ Who was mentioned before you (order matters)
- ✓ Who was mentioned instead of you
- ✓ Which URLs were cited (Perplexity shows these; Wikipedia, Reddit, and G2 dominate)
- ✓ What the model got wrong that you can correct
Why this step matters: Without a baseline, you have no way to measure improvement. Every tool you try after this moment is judged against the manual numbers. Most brands discover their visibility is 10 to 30 points lower than they assumed.
Pro tip: Screenshot every AI answer that contains misinformation about your brand. Wrong pricing, wrong features, wrong founder names. These become your highest-priority content fixes because the model is teaching buyers things that are not true.
Step 4: Choose a Monitoring Tool or Build Your Own
Manual audits work for one-time baselines. They fail as an ongoing system. After the first month, you will either stop tracking or automate it. Choose automation now.
Three paths exist. Pick the one that fits your budget and technical skill.
Path 1: Purpose-built LLM monitoring tools
| Tool | Starting Price | Best For |
|---|---|---|
| Otterly AI | $27/month | Solo marketers and small teams |
| Peec AI | €89/month | Mid-market competitive benchmarking |
| Semrush AI Toolkit | $99/month | Teams already on Semrush |
| Profound | $499/month | Enterprise reporting and controls |
| Ahrefs Brand Radar | Included in Ahrefs plans | Ahrefs customers |
| Scrunch AI | $300/month | GEO agencies |
These tools run your prompt library on schedule, capture raw responses, and chart brand visibility over time. Most cover 5 to 8 LLMs out of the box and flag sentiment automatically.
Path 2: Build your own tracker
Skill: intermediate. Cost: under $100/month. Time: 6 to 12 hours to build.
Use OpenAI, Anthropic, and Google APIs to query models programmatically. Store responses in a Postgres database or Airtable. Run nightly via a scheduled task on Vercel, Railway, or a cron job. Chart the data in a dashboard. Search Engine Land published a full walkthrough on building your own AI search visibility tracker for under $100 per month that is worth reading before you commit.
Path 3: Hybrid approach
Use a free tool like the Semrush AI Visibility Checker or the HubSpot AEO Grader for quarterly audits. Layer on a paid tool only when leadership asks for monthly reporting. Start cheap. Scale when the data starts driving decisions.
Why this step matters: Manual tracking breaks in month two. Automation is the only way to build a reliable trend line. Without a trend line, you cannot tell if a model update hurt you or a competitor outspent you.
Pro tip: Most tools offer a 7-day or 14-day trial. Run the same 30-prompt library through 2 tools during overlapping trials. The one that produces results closest to your manual audit is the tool you trust.
Step 5: Track the 6 Metrics That Matter
Dashboards full of numbers look busy. Most of them do not move the needle. Focus on the 6 metrics that correlate with pipeline.

1. Visibility rate. The percentage of prompts where your brand appears at all. If you test 30 prompts and appear in 12, your visibility rate is 40%. Top-performing brands hit 50% or higher in their core category. Benchmark: 15% minimum. Aim for 30%+.
2. Share of voice. Of all brand mentions across your tracked prompts, what percentage are yours. This is the competitive metric. Read our AI share of voice guide for the full methodology. Top brands hit 15% to 30% in specialized verticals.
3. Citation rate. The percentage of AI answers that link to a URL on your domain. Perplexity and Copilot cite sources openly. ChatGPT cites when web search is enabled. Citation rate is the closest LLM metric to classical ranking.
4. Position. When you are mentioned, where do you land in the list. First mention, third mention, or buried in a paragraph. Order correlates heavily with click-through and recall.
5. Sentiment and accuracy. Is the model describing you correctly. Wrong pricing, wrong features, wrong positioning will cost conversions. Track each error and build a content plan to correct the underlying source the model is pulling from.
6. Coverage by model. Visibility is not uniform across LLMs. You might hit 45% in ChatGPT and 12% in Gemini. Breaking visibility down by model tells you where to invest next.
Report these monthly. Add a seventh metric. Competitor gap. When leadership cares about positioning. Competitor gap is the difference between your visibility rate and your largest competitor's rate for the same prompt set.
Why this step matters: Brands that track 20 metrics make decisions on none. Brands that track 6 get a stack ranking of where to fix content, where to build links, and which prompts drive pipeline.
Stop guessing whether AI models mention your brand. We publish 30 articles per month designed to rank in AI answers, not just Google. Every post is structured for ChatGPT and Perplexity citation out of the gate.
Step 6: Analyze Competitor Mentions and Share of Voice
Your visibility score on its own is meaningless. A 25% visibility rate is a win if competitors sit at 8% and a loss if they sit at 60%. Context turns a number into a decision.
Pick 3 to 5 direct competitors. Not every tool in your space. The ones buyers actually compare you against on sales calls. Ask your sales team if you do not know.
Run the same 30-prompt library with each competitor's name swapped in. If your baseline prompt is "best email marketing tools," the comparison prompts stay identical. You are measuring how the models rank the category, not testing competitor-specific queries.
Build a share of voice table:
| Brand | Mentions | Share of Voice | Position 1 Count |
|---|---|---|---|
| Your Brand | 14 | 18% | 3 |
| Competitor A | 22 | 28% | 8 |
| Competitor B | 19 | 24% | 6 |
| Competitor C | 11 | 14% | 2 |
| Others | 12 | 16% | , |
The Position 1 Count column is where most brands lose money. Being mentioned matters. Being mentioned first matters more. The first brand in a list gets 3x the recall of the second. Top brands push position 1 count above 40% of their total mentions.
Look for:
- ✓ Prompts where you are absent but competitors appear
- ✓ Prompts where the model gets competitor claims wrong
- ✓ Prompts where you appear last in a list of 5
- ✓ Prompts where your description is shorter than competitors
- ✓ URLs cited for competitors but not for you
Each gap is a content opportunity. If the model says "Competitor A offers the cheapest plan at $29" but yours starts at $19, the training data needs correction. That means more Reddit threads, G2 reviews, and comparison pages that surface your pricing. Our guide on brand entity optimization walks through the exact signals models use.
Why this step matters: Tracking your own mentions in isolation is self-flattery. Tracking competitor mentions reveals the actual category share and the playbook competitors are using to win positions you deserve.
Pro tip: Export your share of voice table monthly. The trend line is the story. A brand moving from 8% to 18% share of voice in 90 days is making the right content investments. One stuck at 8% is not.
Step 7: Set Up Alerts and Act on Every Change
The point of tracking is not reporting. It is intervention. A dashboard you look at monthly is worse than useless if competitors are gaining ground daily.
Configure 3 alert types in your monitoring tool:
Alert 1: Visibility drop. Trigger when your visibility rate falls more than 10 percentage points week-over-week. This usually signals a model update or a competitor content push. Investigate within 48 hours.
Alert 2: Sentiment or accuracy shift. Trigger when 3+ prompts return inaccurate information about your brand in the same week. Misinformation compounds. The longer it sits, the more downstream models absorb it.
Alert 3: Competitor surge. Trigger when a competitor's visibility rate increases more than 15 points in 30 days. That pattern almost always correlates with a content campaign, PR push, or paid placement.
Route alerts to Slack or email. Assign ownership. A dashboard nobody watches is a dashboard nobody acts on.
The response playbook is the same regardless of which alert fires:
- Pull the specific prompts that moved
- Check which sources the model cited (Perplexity and Copilot show this explicitly)
- Identify the content gap. Missing page, outdated stat, missing Reddit thread, missing G2 review
- Ship a fix within 2 weeks
Most fixes fall into 3 buckets. Update an existing page with current data. Publish a new page targeting the exact prompt. Earn a mention on a source the model already cites (Reddit, Wikipedia, G2, Product Hunt, industry publications).
For step-by-step tactics on winning citations, read our AI citation readiness checklist and our guide on ranking in AI Overviews.
Why this step matters: LLM brand mentions are not a static score. Model updates, competitor activity, and content decay all move the number weekly. Teams that act on signals win. Teams that report without acting fall behind every quarter.
Pro tip: Add a "tested fix" column to your tracker. When you ship a content update targeting a specific prompt, log the date and the specific change. Re-run the prompt 30 days later. You will see which interventions actually moved the needle and which wasted cycles.
Results: What to Expect
LLM brand mention tracking is a compounding game. The first month feels mechanical. The third month starts showing patterns. The sixth month drives decisions.
Realistic timeline:
- Week 1: Prompt library built and baseline audit complete. You know your starting visibility rate across 5 LLMs.
- Week 2 to 4: Monitoring tool configured. Automated data collection begins. First trend lines emerge.
- Month 2: Competitor gaps identified. First 3 to 5 content interventions shipped against specific prompts.
- Month 3: Measurable visibility movement on intervention prompts. Most brands see a 5 to 10 point lift on prompts where they actively shipped fixes.
- Month 6: Double-digit share of voice gains possible if content and off-page signals compound. Brands that publish 20+ pieces per month routinely outpace peers here.
- Month 12: Category leadership position. Brands at the top of their LLM visibility curve typically hit 30% to 50% visibility rates in core queries.
Do not expect overnight shifts. Model updates can wipe out a month of gains in a single release. The brands that win are the ones still publishing and monitoring when most competitors quit.
Troubleshooting Common Issues
Problem: Your brand appears in some prompts but not consistently across repeat queries. Solution: This is temperature variance. Run each prompt 3 to 5 times and average the result. Most LLM monitoring tools handle this automatically by querying the same prompt multiple times per cycle.
Problem: You appear with web search enabled but not with it disabled. Solution: Your brand is not part of the model's training data yet. Focus on sources AI models crawl: Wikipedia, Reddit, G2, Crunchbase, and high-authority industry sites. Our guide on building a citation-worthy brand covers the exact sources.
Problem: The model describes your product inaccurately (wrong pricing, wrong features). Solution: Find the source. Usually an outdated page on your site, a stale review, or a competitor's comparison page misrepresenting you. Update your own pages first, then request corrections on third-party sources.
Problem: Visibility looks great on ChatGPT but zero on Perplexity. Solution: Perplexity weighs recent, citation-heavy sources more than training data. Publish fresh content monthly. Structure articles for source citation: short paragraphs, clear claims, original data.
Problem: Your monitoring tool shows different numbers than your manual audit. Solution: Check the model versions, the query volume, and the search toggle settings. Most discrepancies come from tools using different models or disabling web search where you enabled it.
What practitioners are saying on X
Systems and fundamentals still compound; AI search adds new KPIs.
- @jakezward (Feb 2026): 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers as a KPI, proprietary data as a moat, and content refresh beating net-new AI slop. See the post on X.
- @hridoyreh (Mar 2026): Widely shared SEO skill tree: foundations, research, technical, on-page, content, links, AI SEO/GEO, analytics, UX, brand, programmatic — useful map for stats and how-to posts. See the post on X.
- @HlynurStefDev (Jul 2026): Public case: niche site traffic jumped from ~18 to 4,162 Google visits/month after focused technical/on-page SEO work (GSC screenshots claimed) — reminds that fundamentals still move numbers. See the post on X.
Grok, AI Overviews, and multi-engine visibility
For topics covered in “track llm brand mentions”, multi-engine visibility still starts with clear definitions, sourced statistics, and extractable section answers. Grok additionally factors live X discussion — keep public claims consistent with this page.
- Google AI Overviews: Use passage-ready answers and structured data.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Publish content built for Google and AI citations. theStacc’s Content SEO module ships SEO-scored articles structured for rankings and generative engines — including clearer entity pages models like Grok can quote.
How to measure multi-engine visibility in 2026
Split KPIs across classic search, AI Overview citations, chat referrals, and Grok-ready brand accuracy.
- GSC: non-brand clicks and query annotations.
- Citations: named in AI answers?
- Referrals: ChatGPT / Perplexity in GA4.
- Grok: on-site claims match public X discussion.
Frequently Asked Questions
Audit manually once per quarter. Run automated tracking weekly. Set real-time alerts for visibility drops of 10+ points. Monthly reporting works for most brands, but high-velocity categories (SaaS, ecommerce) benefit from weekly review.
Yes, partially. Free tools like the HubSpot AEO Grader, Semrush AI Search Visibility Checker, and manual spreadsheet audits give you a baseline. For ongoing tracking across 5+ models with alerts, expect to pay $27 to $99 per month minimum for a dedicated tool.
ChatGPT first because of scale. Perplexity second because it cites sources openly. Google Gemini third because it powers AI Overviews. Claude and Copilot matter most for B2B and enterprise buyers. Track all 5 if budget allows.
15% is the floor. 30% is strong. 50%+ is category leadership. These numbers assume a well-built prompt library of 30+ queries across your core category. Narrow prompt lists inflate the number artificially.
No. Fewer than 10% of URLs cited in ChatGPT, Gemini, and Copilot also rank in the top 10 Google organic results for the same query. AI citation depends on different signals: brand mentions, Wikipedia presence, Reddit threads, and structured content. Read our guide on brand mentions vs backlinks.
Individual prompts can shift in 30 days when you fix specific sources. Category-wide visibility gains take 3 to 6 months of consistent publishing and off-page work. Model updates can move scores overnight in either direction.
Start Tracking Today
Now you know how to track LLM brand mentions across every major AI platform. You have a 30-prompt library, a baseline audit plan, a tool shortlist, the 6 metrics that matter, a share of voice framework, and an alert system.
Which step are you starting with first. Building the prompt library, running the manual audit, or picking a monitoring tool? The teams that win in AI search are the ones that pick one and start this week.
Want 30 blog posts per month engineered to rank in LLM answers? We handle the prompts, the writing, the publishing, and the internal linking. You get measurable LLM citations inside 90 days.
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @jakezward on X — 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers
- [3] @alexgroberman on X — Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category
- [4] Referenced source — searchengineland.com

Researched, written, and published articles that compound organic traffic.
Weekly local SEO teardowns
One practical email a week. Map Pack, GBP, AI Overviews — no fluff. Unsubscribe anytime.