Programmatic SEO local data sources, schema, enrichment, and quality controls for location pages that rank in 2026. Real APIs, real examples, real rules.
Most programmatic SEO projects do not fail at the template. They fail at the data.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
A location page that swaps "Dallas" for "Denver" and ships 500 variants is the fastest way to trigger Google's Scaled Content Abuse policy. The March 2026 core update deindexed thousands of these sites overnight. Some lost 60% to 90% of organic traffic in a single week.
But programmatic SEO is not dead. Yelp still pulls in millions of monthly visits from 150-plus city pages. Zillow's neighborhood pages dominate real estate SERPs. Wise ranks for every currency conversion query. The difference is the data layer.
This guide is about the data layer. Specifically, the data layer for local programmatic SEO: city pages, service-area pages, neighborhood guides, and any template that takes one head term and multiplies it across geography.
We publish 3,500+ blogs across 70+ industries. Our average SEO score is 92%. We build location-based programmatic pages for service businesses, agencies, and multi-location brands. The patterns below come from what actually ships and ranks.
Here is what you will learn:
- The 6 categories of programmatic SEO local data and where to source each
- How to combine free public datasets with paid APIs without overpaying
- The 60/40 rule for unique-vs-templated content (and why 25 to 30% is the new floor)
- LocalBusiness schema patterns that signal trust at scale
- Quality controls that prevent thin-content deindexing
- Real architecture patterns from companies generating millions of visits
What Programmatic SEO Local Data Actually Means
Programmatic SEO local data is the structured information that makes each location-targeted page unique. The template stays the same across thousands of variants. The data is what changes per page and what gives each URL a reason to exist.
A bad location page swaps the city name in 3 places. A good location page pulls in neighborhood demographics, competitor density, average pricing, climate context, license requirements, and verified business listings. The first is thin content. The second is a useful resource.
Google's scaled content abuse policy targets "content created primarily for search engines rather than people." The policy does not target templates. It targets pages with no unique value. The data layer is what separates the two.
The bar in 2026 is concrete. Google's scaled content abuse policy explicitly targets pages "generated at scale" with limited unique value. Industry tracking shows sites generating thousands of near-identical pages saw ranking losses of 60% to 90% after the March 2026 update. The survivors share one feature: real data differentiation. Verified listings. Live pricing. Proprietary inventory. First-party reviews.
Why Local Data Is Different from Regular Programmatic Data
A pricing comparison page can pull from one API. A location page needs 5 to 8 data sources to feel complete.
Local intent is dense. A user searching "plumber in Portland" wants:
- Verified businesses serving Portland
- Neighborhoods covered
- License or insurance requirements specific to Oregon
- Average pricing in the Portland market
- Reviews and ratings
- Hours of operation
- Service categories
Each of those items comes from a different source. The data layer for local programmatic SEO is a stack, not a single feed.
For context on how location pages fit into a broader strategy, see our local SEO guide.
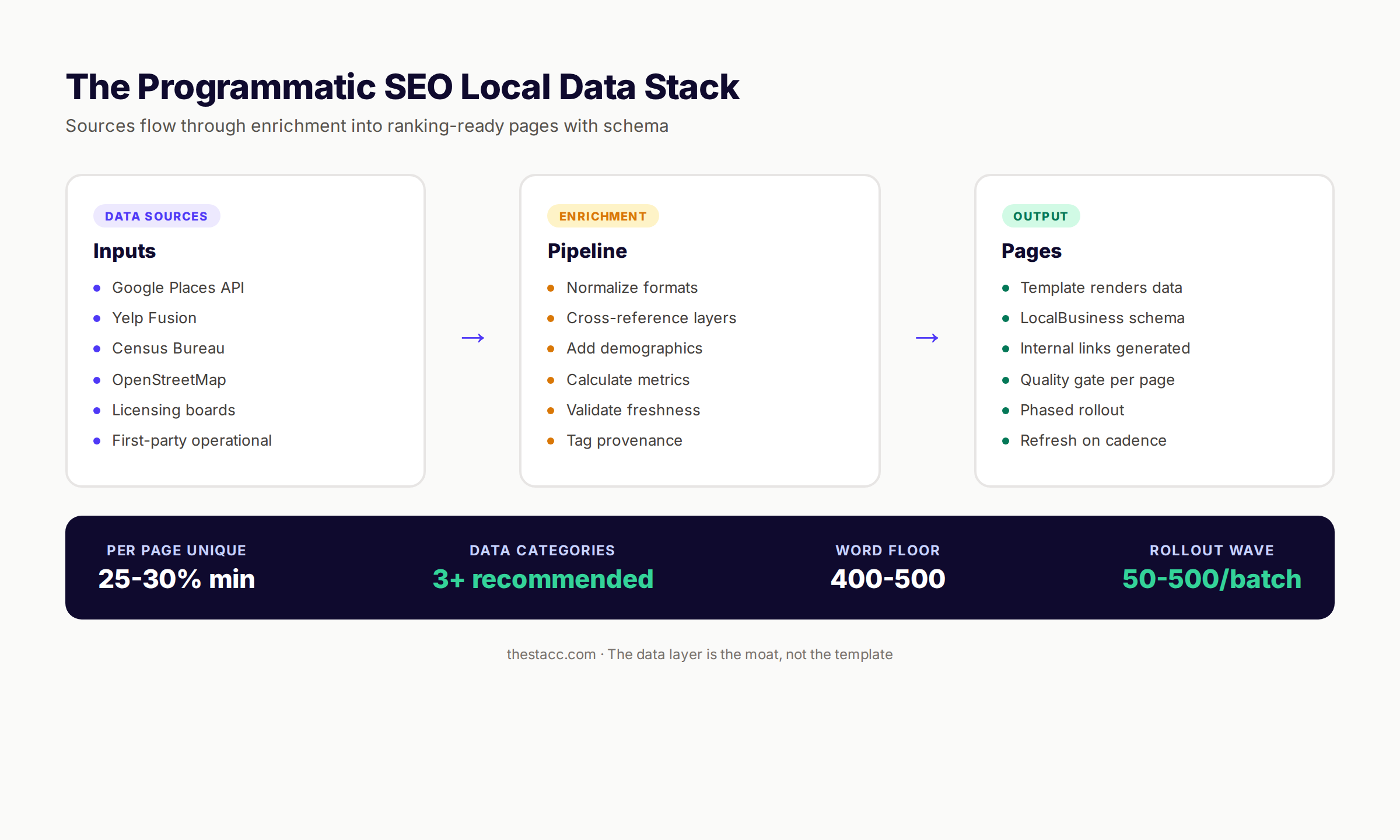
The 6 Categories of Programmatic SEO Local Data
Every defensible local programmatic page draws from at least 3 of these 6 categories. Pages built on only 1 or 2 categories tend to feel thin even when the word count is high.
| Category | What It Provides | Cost Range | Update Frequency |
|---|---|---|---|
| Business listings | Verified NAP, hours, categories | Free to $$$$ | Daily |
| Demographic & census | Population, income, age, density | Free | Annual |
| Geographic & spatial | Neighborhoods, boundaries, distance | Free to $$ | Quarterly |
| Reviews & ratings | Star averages, review counts, sentiment | Free to $$$ | Real-time |
| Regulatory & licensing | Permits, certifications, local rules | Free | Annual |
| First-party operational | Your pricing, availability, capacity | Free (internal) | Real-time |
The strongest pages combine first-party operational data with verified third-party data. Yelp's category pages work because they merge first-party reviews with verified business listings. Zillow's neighborhood pages work because they merge first-party listing inventory with public census data.
Category 1: Business Listings Data
Business listings are the spine of any local programmatic SEO page. Without verified NAP data (name, address, phone), the page lacks the entities Google uses to validate local intent.
Free or low-cost sources:
- Google Places API (Maps Platform): broad coverage, frequent updates from businesses and users
- OpenStreetMap: free, community-maintained, strong in some regions
- U.S. SBA business directory: free, federal-level only
Paid commercial sources:
- Yelp Fusion API: rich reviews, photos, business attributes
- Foursquare Places API: strong on behavioral signals, venue categories
- SafeGraph or Data Axle: enterprise POI data with verified records
- Major data aggregators (Acxiom, Foursquare, Localeze, Express Update): supply hundreds of downstream directories
Google Places remains the default for broad coverage. Yelp wins on review density. Foursquare wins on behavioral data. Pick based on which data type drives the most user value on your page.
For consumer-facing pages, layer Yelp or Google reviews on top of base listings. For B2B pages, layer Crunchbase or LinkedIn data instead.
Category 2: Demographic and Census Data
Census data adds market context that listings alone cannot provide. Population, median income, age distribution, household composition, and employment statistics give a location page a market-level frame.
Free U.S. sources:
- U.S. Census Bureau API: population, housing, industry size
- U.S. Bureau of Labor Statistics (BLS): employment and salary data, updated monthly
- American Community Survey (ACS): granular demographic detail at ZIP and tract level
- data.gov: federated portal across hundreds of federal datasets
International equivalents:
- EU Open Data Portal for European geographies
- UK Office for National Statistics for British data
- Statistics Canada for Canadian markets
Census data is free, structured, and reliable. The downside is the update frequency. Annual or 5-year estimates do not refresh fast enough to feel current. Use census data for context, not for any claim that depends on real-time accuracy.
Category 3: Geographic and Spatial Data
Geographic data is what separates a "city page" from a true location page. Neighborhoods, ZIP codes, school districts, and service-area polygons give your page geographic specificity.
Free sources:
- OpenStreetMap: neighborhoods, boundaries, points of interest
- Natural Earth: country and state-level boundaries
- TIGER/Line files from the U.S. Census: detailed boundary data
- Wikipedia geographic infoboxes: structured location data
Paid sources:
- Mapbox Geocoding API: high-quality boundaries and reverse geocoding
- HERE Maps API: enterprise spatial data
- Mapzen and Pelias for open-source self-hosted geocoding
Pulling neighborhood names from OpenStreetMap and rendering them in your page is a strong move. A "Plumbers in Portland" page that lists 14 named Portland neighborhoods serves a clearly different intent than a generic city page.
For more on how to scale local pages, see our local SEO checklist.
Category 4: Reviews and Ratings
Review data adds social proof that no template alone can provide. Star averages, review counts, and recent sentiment give a page freshness signals and user-generated uniqueness.
Sources:
- Yelp Fusion API: deep review database with sentiment tagging
- Google Places API: review count and average rating per business
- Trustpilot API: B2B review focus
- First-party reviews collected through your platform
Layering reviews on a local page is one of the strongest uniqueness signals. Two locations with identical demographics will have different reviews. That difference alone can push a page past the 25 to 30% uniqueness floor required for survival.
The catch is freshness. Stale review data ages a page. Set a refresh cadence of at least once per quarter, ideally monthly.
Category 5: Regulatory and Licensing Data
Regulatory data is the most underused category in local programmatic SEO. It is also the most defensible.
A "Plumber in Texas" page that explains Texas State Board of Plumbing Examiners requirements, license fees, and insurance minimums is genuinely useful. A page that skips this is generic.
Sources by vertical:
- State licensing boards (free, varies by state)
- Federal regulatory databases like FCC, FDA, USDA
- State Department of Insurance for insurance verification
- Local permit databases for construction and home services
- Bar association directories for legal services
This data is hard to scrape and harder to maintain. That is exactly why it is defensible. Competitors with no manual research operation cannot replicate it.
Category 6: First-Party Operational Data
First-party data is the strongest category because no competitor can access it. Your pricing, your availability, your capacity, your service area, your team, your past projects.
What counts as first-party:
- Your service catalog and pricing per region
- Your scheduling and availability data
- Your customer review database
- Your case studies and past project data
- Your team profiles and certifications
- Your supply chain and inventory by location
A page that surfaces your live pricing for that ZIP code, your next available appointment, and your past 3 projects in that neighborhood is impossible for a competitor to replicate by template.
Stop writing. Start ranking. Stacc publishes 30 SEO articles per month for $99 with built-in local pages.

The 60/40 Rule (and Why 25 to 30% Is the Real Floor)
The 60/40 rule says 60% of a programmatic page should be dynamically generated from your data. The remaining 40% can be templated text providing methodology, framing, and context.
That rule still holds for most projects. But the floor has moved. The March 2026 core update made one threshold concrete: at least 25 to 30% of the text and data on every page must be unique to that specific URL. Below that floor, scaled content abuse risk spikes.
For local pages, hitting 25 to 30% uniqueness requires 4 to 6 dynamic data blocks per page minimum. A single dynamic NAP block plus a templated FAQ section is not enough.
What Counts as Unique vs Templated
Unique content includes:
- Per-location business listings (variable count, variable identities)
- Per-location reviews (different review text per page)
- Per-location demographic data (different numbers per page)
- Per-location regulatory data (different rules per state)
- Per-location operational data (different pricing, availability, schedule)
Templated content includes:
- Header navigation, footer, sidebar
- Generic introduction paragraphs that mention the city
- FAQ questions that recycle across all pages
- Static methodology explanations
If your page is 800 words of templated framing wrapping 200 words of data, you are at 25% uniqueness. That is the floor. The page is at risk. Push it higher.
How to Audit Uniqueness
Run this check on any programmatic template before scaling past 50 pages:
- Generate 5 variant pages from the template
- Extract the visible text from each page
- Identify which sentences appear in 3 or more variants
- Calculate the percentage of text that is variant-unique
- If under 35%, redesign the template
If your sample of 5 variants shows the same 10 sentences on every page, those 10 sentences are templated. Multiply that by 1,000 variants and Google sees 1,000 pages with the same 10 sentences. That is the duplicate content signal that triggers deindexing.
A Working Uniqueness Formula
| Page Section | % of Page | Source | Unique Per URL? |
|---|---|---|---|
| H1 and meta description | 5% | Template + variable | Yes |
| Hero introduction | 8% | Dynamic from data + variable framing | Yes (75%) |
| Local listings block | 25% | Business listings API | Yes (100%) |
| Demographic context | 12% | Census API | Yes (100%) |
| Reviews block | 15% | Reviews API | Yes (100%) |
| Service or category list | 10% | Internal database | Yes (90%) |
| Regulatory block | 8% | Manual or scraped | Yes (state level) |
| FAQ | 10% | Template with dynamic answers | Partial (40%) |
| Methodology and disclosure | 7% | Templated | No |
In this distribution, roughly 70% of the page content is unique per URL. That is well above the 30% floor and gives ranking signals room to breathe.
For more on how page structure affects ranking, see our blog post structure for SEO guide.
LocalBusiness Schema for Programmatic Pages
Schema is non-negotiable for local programmatic SEO. Pages without schema lose the rich result eligibility that makes location pages competitive in SERPs.
The base schema type for any location page is LocalBusiness or one of its 100+ subtypes. Pick the most specific subtype available. Plumber outranks LocalBusiness. Dentist outranks MedicalBusiness. Specificity helps.
The Minimum Viable LocalBusiness Schema
Every programmatic local page should output this baseline JSON-LD:
{
"@context": "https://schema.org",
"@type": "Plumber",
"name": "ACME Plumbing",
"address": {
"@type": "PostalAddress",
"streetAddress": "123 Main St",
"addressLocality": "Portland",
"addressRegion": "OR",
"postalCode": "97201",
"addressCountry": "US"
},
"telephone": "+1-503-555-0100",
"url": "https://example.com/plumbers/portland",
"openingHours": "Mo-Fr 08:00-18:00",
"geo": {
"@type": "GeoCoordinates",
"latitude": 45.5152,
"longitude": -122.6784
},
"areaServed": {
"@type": "City",
"name": "Portland"
}
}For directory-style pages listing multiple businesses, use an ItemList with embedded LocalBusiness items. Each entry should carry its own structured data.
Adding Reviews to Schema
If your page aggregates reviews, add aggregateRating. If your page lists individual reviews, add review arrays. Both are eligible for rich snippets.
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"reviewCount": "127"
}Never invent ratings. Google's review snippet guidelines verify aggregate ratings against the visible page content. Mismatched data triggers manual penalties.
For more on schema patterns, see our schema markup generator.
Place Schema for Geographic Pages
For pages targeting a place (neighborhood, district, region) rather than a business, use Place schema. This applies to neighborhood guides, "best restaurants in [neighborhood]" pages, and area-served roundups.
{
"@context": "https://schema.org",
"@type": "Place",
"name": "Pearl District",
"containedInPlace": {
"@type": "City",
"name": "Portland"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": 45.5294,
"longitude": -122.6831
}
}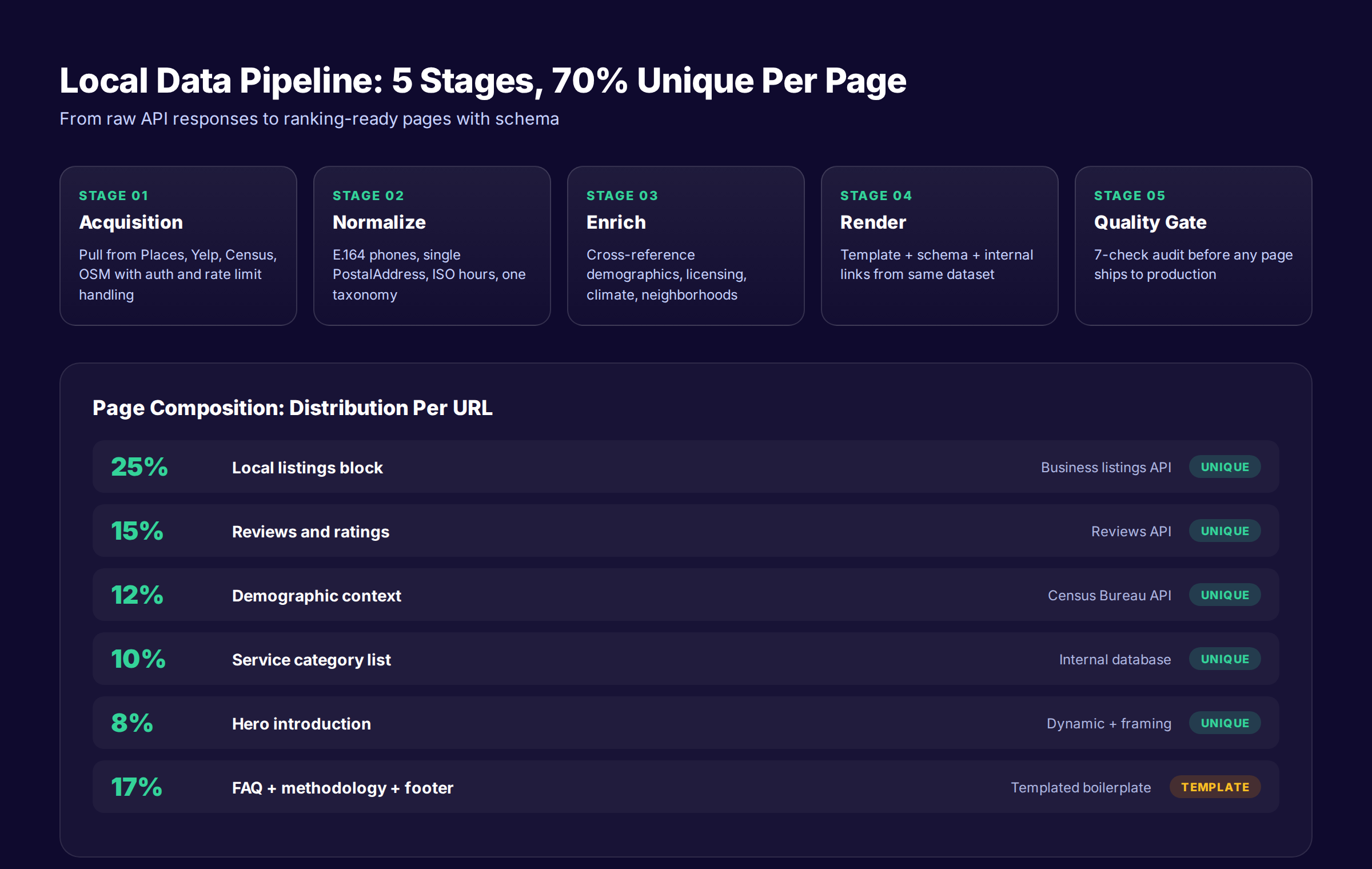
Building the Local Data Pipeline
A working programmatic SEO local data pipeline has 5 stages. Skip a stage and you ship thin pages. Run all 5 and you ship pages that survive core updates.
Stage 1: Data Acquisition
This is where you pull data from your chosen sources. The pipeline must handle:
- Authentication and rate limits per API
- Pagination across large result sets
- Error handling for missing or malformed responses
- Storage in a normalized format
- Provenance tracking (where each data point came from)
Most teams use Airtable, Google Sheets, or a Postgres database for staging. Pick based on volume. Under 5,000 rows, Airtable is fine. Over that, use Postgres.
Stage 2: Data Normalization
Raw API data is rarely clean. Phone numbers format differently per source. Addresses use different field names. Categories use different taxonomies. Normalization is the unglamorous middle step that determines whether your template can render anything useful.
Normalize:
- Phone numbers to E.164 format
- Addresses to a single PostalAddress schema
- Categories to one internal taxonomy (Schema.org types work well)
- Coordinates to decimal degrees
- Hours to ISO 8601 duration patterns
A normalized dataset can drive multiple templates. A messy dataset can drive none.
Stage 3: Data Enrichment
This is where thin data becomes useful data. Take a base layer like business listings and cross-reference it with:
- Census demographics for the ZIP code
- Climate or weather context for the region
- License or permit data for the state
- Population density for the city
- Median income for the neighborhood
Each enrichment layer adds uniqueness per page. A city page with population data is fine. A city page with population + median income + competitor density + license requirements + climate context + average pricing is excellent.
For more on combining data sources, see our content gap analysis guide.
Stage 4: Template Rendering
The template consumes normalized, enriched data and outputs HTML. Render rules:
- Conditional blocks: if data exists, render it; if not, skip the block entirely
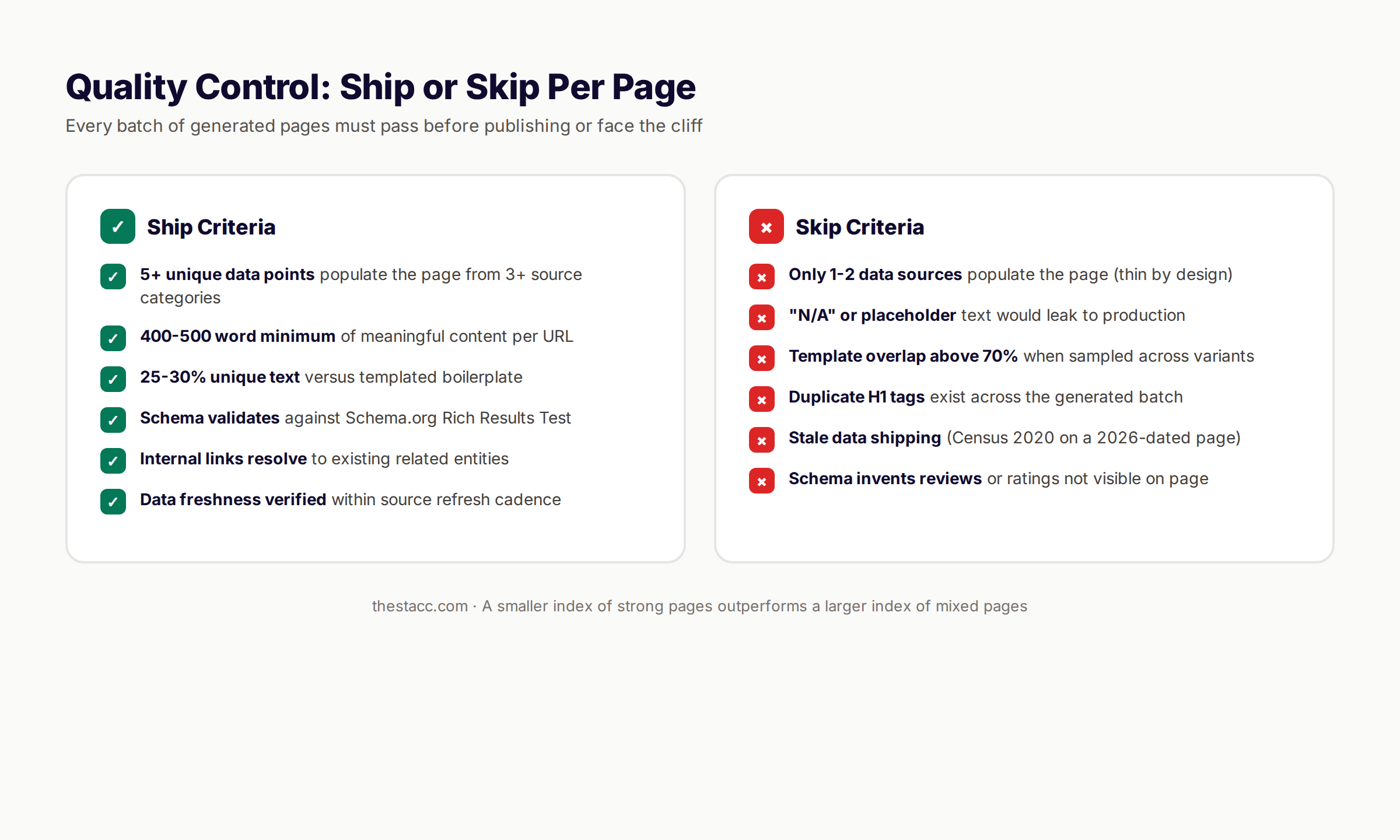
- No "N/A" placeholders that ship to production
- No empty sections that signal thin content
- Schema generated from the same data that drives the visible content
- Internal links generated from related entities in the dataset
Static site generators (Astro, Next.js, Hugo) work well. So do Webflow CMS and WordPress with Advanced Custom Fields. Pick the stack that matches your team's deployment maturity.
Stage 5: Quality Control
Quality control is what prevents the cliff. Every batch of generated pages should pass these checks before publishing:
- ✓ Minimum word count per page (400 to 500 minimum)
- ✓ Minimum unique data points per page (5 to 8 minimum)
- ✓ Maximum template overlap (no more than 70%)
- ✓ All schema validates against schema.org
- ✓ All internal links resolve
- ✓ No duplicate H1 tags across the batch
- ✓ No "N/A" or "[city]" placeholder leakage
Automate every check. Manual review does not scale past 50 pages. A simple node script that scans the batch for the 7 conditions above catches 90% of common failures.
Build your local data stack the smart way. Stacc publishes location pages with built-in schema, NAP data, and review integration for $99/month.
Real Examples: How Top Sites Use Local Data
Theory is helpful. Real numbers are more helpful. The pages below all use programmatic SEO local data at scale and continue to rank after the March 2026 core update.
Yelp: 150+ City Pages with Verified Listings
Yelp's top-level city pages target queries like "Restaurants in Boston" and "Plumbers in San Francisco." Each city page is a directory hub with subcategory pages for restaurants, shopping, services, and nightlife.
The data layer:
- First-party listings: 12 million+ active businesses
- First-party reviews: 244 million reviews
- Business categories: a custom taxonomy 2,000+ deep
- Hours, photos, and amenities per business
The reason Yelp survives algorithm updates is not the template. It is the review volume. No competitor can replicate 244 million first-party reviews. The data layer is the moat.
Zillow: Neighborhood Pages with Real Inventory
Zillow's neighborhood pages target queries like "Homes in Pearl District Portland" and "Apartments in Park Slope Brooklyn." Each page combines:
- First-party listing inventory (live, updated continuously)
- Median home prices and trends
- School district data from public sources
- Walkability and transit scores
- Census demographics
- Crime stats from public sources
The combination is impossible for a competitor without listing inventory to match. Zillow's listings are the proprietary data. Everything else is enrichment.
TripAdvisor: 226 Million Visits from Place Pages
TripAdvisor runs programmatic pages for hotels, restaurants, and attractions in tens of thousands of destinations. The data layer:
- First-party reviews and ratings
- Business listings with photos, hours, amenities
- Geographic data: neighborhoods, attractions, distances
- Booking integration showing live pricing
TripAdvisor's review volume serves the same role as Yelp's. The review database is the moat. The templates are interchangeable.
Wise: Currency Pages with Real-Time Rates
Wise dominates every "X to Y exchange rate" query. The pages combine:
- Live exchange rate data (first-party, real-time)
- Historical rate charts
- Fee comparisons with traditional banks
- Currency context and conversion examples
Wise's pages rank because the exchange rate data is genuinely real-time and the fee data is proprietary. A competitor cannot match either by template alone.
Pattern: The Moat Is the Data, Not the Template
Across these examples, one pattern repeats. The defensible asset is the data layer, not the page template. Templates can be copied in a weekend. Datasets like 244 million reviews or live exchange rates take years to build.
For local programmatic SEO, the same principle applies. Your moat is the combination of first-party data (your operations, your customers, your inventory) and the integrations that enrich it (Census, Places, Reviews APIs).
For more on what makes content defensible, see our content marketing strategy guide.
Common Failure Patterns to Avoid
Most local programmatic SEO failures repeat the same 6 mistakes. Each one is fixable if caught early.
Failure 1: Pulling Data from One Source Only
A location page driven by one API is thin by definition. The page might be 2,000 words, but the unique data is one block. Google sees the page for what it is.
Fix: Combine at least 3 of the 6 data categories per page.
Failure 2: Renting Data Without Adding Value
Pulling business listings from Yelp and rendering them on your own page without enrichment is a copy job. Yelp already ranks for those queries with the same data and more.
Fix: Add at least 2 enrichment layers (demographics, licensing, your own analysis) on top of any third-party feed.
Failure 3: Letting Stale Data Ship
Census data from 2020 on a page dated 2026 is a trust signal in the wrong direction. Yelp reviews from 2019 on a 2026 page is the same problem.
Fix: Display the data refresh date prominently. Set automated refresh cadences per source. Audit quarterly.
Failure 4: No Quality Floor on Pages
Some pages will have rich data. Some will have almost none. Without a quality floor, the thin pages drag down the whole subdirectory.
Fix: Set a minimum data threshold. If a variant cannot meet 5 unique data points, do not publish that variant. A smaller index of strong pages outperforms a larger index of mixed pages.
Failure 5: Indexing Pages Before They Are Ready
Pushing 2,000 pages live in one day looks suspicious. Google's crawl pattern flags sudden index bloat.
Fix: Roll out in waves. Start with 50 pages. Confirm they index and rank. Scale to 200. Confirm again. Scale to 1,000. Phased rollouts also let you fix template issues at lower scale.
Failure 6: Skipping Schema
Programmatic pages without schema lose the rich result eligibility that drives 30 to 50% of clicks at the SERP level.
Fix: Generate schema from the same data layer that drives the visible content. Validate every batch against Schema.org and Google's Rich Results Test.
For technical implementation, see our technical SEO checklist.
A Practical Build Plan: 6 Phases
This is the sequence we use when building local programmatic SEO for a new client or product. It takes 4 to 8 weeks depending on scope.
Phase 1: Keyword Pattern Research (Week 1)
Identify the head term + modifier pattern. Validate search volume across at least 50 modifier values. Confirm intent consistency. Build the master keyword sheet.
Phase 2: Data Source Selection (Week 1 to 2)
Pick 3 to 5 data sources covering the 6 categories. Run cost projections for each. Sign up for APIs and test rate limits. Stage sample data for 10 variants.
Phase 3: Template Design (Week 2 to 3)
Build 3 to 5 sample pages by hand. Write them as if they were regular articles. Identify which sections are template vs dynamic. Lock the structure before writing any code.
Phase 4: Pipeline Build (Week 3 to 5)
Implement the 5-stage pipeline: acquisition, normalization, enrichment, rendering, QC. Test on a batch of 50 pages. Audit uniqueness, schema validity, and link resolution.
Phase 5: Phased Rollout (Week 5 to 7)
Publish 50 pages. Monitor indexing and rankings for 1 to 2 weeks. Scale to 200. Monitor again. Scale to your full set in batches no larger than 500 per week.
Phase 6: Maintenance and Refresh (Ongoing)
Set refresh cadences per data source. Monitor ranking distribution monthly. Identify thin pages and either enrich or deindex them. Update schema as Schema.org evolves.
For a related framework, see our programmatic SEO complete guide.
Tools and APIs by Budget
The cost of building a local programmatic SEO data layer varies wildly. Here is what the budgets actually look like.
Free Tier (Under $50/month)
| Tool | Use Case | Limits |
|---|---|---|
| OpenStreetMap | Geographic boundaries, neighborhoods | None (rate-limited) |
| U.S. Census API | Demographic data | None |
| BLS API | Employment data | None |
| Google Places API (free tier) | Basic business listings | $200 free credit/month |
| Schema.org | Schema vocabulary | Free, no API |
A scrappy build with OpenStreetMap + Census + Google's free Places credit can power 200 to 500 location pages.
Starter Tier ($50 to $500/month)
| Tool | Use Case | Approx Cost |
|---|---|---|
| Google Places API (paid) | Verified listings at scale | $100 to $400/month |
| Yelp Fusion API | Reviews and ratings | Negotiated |
| Foursquare Places | Behavioral signals | $100 to $300/month |
| Mapbox | Geocoding and boundaries | $50 to $200/month |
The starter tier supports 500 to 5,000 location pages with rich data.
Growth Tier ($500 to $5,000/month)
| Tool | Use Case | Approx Cost |
|---|---|---|
| SafeGraph Places | Enterprise POI data | $500 to $2,000/month |
| Data Axle / Express Update | Verified business data | $500 to $3,000/month |
| Cognism | B2B contact data | $500 to $2,000/month |
| Crunchbase API | Company data | $500/month |
The growth tier supports 5,000+ pages with deeply enriched data and is where most multi-location brands operate.
For a comparison of broader SEO tools, see best AI SEO tools.
What practitioners are saying on X
AI search advice ages quickly. Here is high-signal public discussion from SEO and growth operators — context for your roadmap, not a substitute for primary data.
- @noelcetaSEO (Sep 2025): Local SEO playbook still centers complete GBP, NAP consistency, quality citations, local keywords, location content, review velocity, and local links. See the post on X.
- @irentdumpsters (Jan 2026): Most businesses have a GBP; few fully optimize every ranking-relevant section for Map Pack visibility. See the post on X.
- @EldarCohenSEO (Jul 2026): 2026 WhiteSpark-oriented reminder: primary Google Business category is a top Map Pack ranking factor — wrong primary category can erase visibility for money queries. See the post on X.
Grok, AI Overviews, and multi-engine visibility
Local topics like “programmatic seo local data” get cited when GBP, NAP, reviews, and service-area steps are concrete. Grok mixes those web facts with Map Pack operator advice circulating on X.
- Google AI Overviews: Use passage-ready answers, tables, and FAQ schema where relevant.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Rank higher in the Map Pack without a full-time local SEO hire. theStacc’s Local SEO module handles daily GBP posts, review reply workflows, and local visibility tracking — built for service businesses that need calls, not vanity rankings.
FAQ
Programmatic SEO local data is the structured information that powers location-targeted pages at scale. It includes business listings, demographics, geographic boundaries, reviews, licensing, and first-party operational data. The data layer is what makes each templated page unique per URL.
At least 25 to 30% of the visible content must be unique per URL after the March 2026 core update. Practically, that means 4 to 6 dynamic data blocks per page minimum. Pages that fall below that floor are at elevated risk of being flagged under Google's scaled content abuse policy.
Google Places API has the broadest coverage and most frequent updates. Yelp Fusion is strongest for reviews and consumer business data. Foursquare is strongest for behavioral signals. SafeGraph and Data Axle are stronger for enterprise B2B and verified records. Pick based on whether your pages need consumer or B2B coverage and how heavily reviews factor in.
Web scraping is legally and technically risky. It also produces data that competitors can replicate, so it adds little defensibility. The stronger move is to combine free public datasets (Census, BLS, OpenStreetMap) with paid APIs (Places, Yelp, Foursquare) and your own first-party data.
There is no hard cap. The constraints are data quality and rollout pace. Publish in batches of 50 to 500. Monitor indexing and ranking for 1 to 2 weeks per batch. If pages are indexing and the SERP positions look healthy, continue. If thin pages are not indexing, fix the data layer before scaling.
Yes for any page representing a specific business. Use the most specific subtype available (Plumber, Dentist, Restaurant) rather than generic LocalBusiness. For pages representing places rather than businesses, use Place schema instead.
Reviews and ratings: monthly minimum, weekly ideal. Business listings: monthly. Demographics: annually (matches Census release cadence). Operational data like pricing and availability: real-time. Set automated refresh jobs per source and audit quarterly.
Bottom Line
Programmatic SEO local data is the difference between a page that ranks and a page that gets deindexed. The template is interchangeable. The data layer is the moat.
In 2026, the bar is concrete. Combine at least 3 of the 6 data categories. Hit 25 to 30% unique content minimum per URL. Layer schema on the same data that drives the visible content. Roll out in waves and audit quality before scaling.
The companies that survive every core update share one feature: they own data their competitors cannot replicate. First-party reviews, live inventory, proprietary pricing, verified listings. Build that data layer first. The pages will follow.
See how Stacc publishes location pages at scale →
Related Tools & Resources
Free SEO Tools:
Best Lists:
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @noelcetaSEO on X — Local SEO playbook still centers complete GBP, NAP consistency, quality citations, local keywords, location content, rev
- [3] @irentdumpsters on X — Most businesses have a GBP; few fully optimize every ranking-relevant section for Map Pack visibility.
- [4] @EldarCohenSEO on X — 2026 WhiteSpark-oriented reminder: primary Google Business category is a top Map Pack ranking factor — wrong primary cat
- [5] Referenced source — developers.google.com
Researched, written, and published articles that compound organic traffic.