AI agents like ChatGPT, Claude, and Perplexity now drive B2B and B2C buying decisions. The 2026 guide to getting cited and winning agentic visibility.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
By Q4 2026, more than half of high-consideration B2B purchases will involve an AI agent at some point in the decision path. That is not a forecast from a vendor with skin in the game. It is what we see in our own publishing data, in the public statements of Anthropic, OpenAI, and Perplexity, and in the buyer interviews our customers run every week.
The shift is not loud. There is no banner ad announcing it. A CFO opens Claude and types "compare CRMs under $100 per seat with HubSpot-style automation." A procurement analyst pastes a vendor longlist into ChatGPT and asks for a scored shortlist. A consumer asks Perplexity "what is the best running shoe under $130 for flat feet" and clicks the agent's top pick. In every case, the agent did the research, and the buyer trusted it.
That is the new buyer journey. AI agents now sit between your content and your customer.
We have published 3,500+ SEO articles across 70+ industries since 2023. In Q1 2026 we analyzed how 1,200 of our pages performed inside ChatGPT, Claude, and Perplexity responses. The pattern was clear: pages with the same keyword target performed very differently inside agent answers. Some got cited five times a week. Others got nothing. The variable was not topic. It was structure.
This guide explains exactly what changed, why it matters, and what to do about it.
Here is what you will learn:
- What "AI agents in buyer decisions" actually means in 2026, with real examples from both sides of the table
- How B2B procurement is being delegated to AI agents — and what wins inside a CFO's Claude window
- How agentic shopping works on the B2C side, including OpenAI Operator, Perplexity Shopping, and Anthropic computer use
- What content these agents cite when making recommendations, ranked by frequency
- The six content properties that get cited by buyer-side AI agents
- The Agent-Citable Content Matrix — a scoring framework for any page you publish
- A 90-day tactical playbook that moves real commercial pages from invisible to cited
Want every page on your site agent-citable without rewriting them yourself? Stacc publishes 30 schema-rich, citation-ready articles every month — built for AI agents and human readers.
Table of Contents
- Chapter 1: What "AI Agents in Buyer Decisions" Means in 2026
- Chapter 2: B2B Procurement by AI Agent — A Real Example
- Chapter 3: Agentic Shopping on the B2C Side
- Chapter 4: What Content AI Agents Actually Cite
- Chapter 5: The Six Properties of Agent-Citable Content
- Chapter 6: The Agent-Citable Content Matrix
- Chapter 7: The 90-Day Agentic Visibility Playbook
- Chapter 8: Frequently Asked Questions
Chapter 1: What "AI Agents in Buyer Decisions" Means in 2026
AI agents in buyer decisions are autonomous AI systems — ChatGPT, Claude, Perplexity, Gemini, and agentic shopping assistants — that research products, compare vendors, and recommend purchases on behalf of a human buyer.
They read sources, extract entities, score options, and surface a ranked answer. The human acts on what the agent shows them, which means the agent — not the buyer — is now the primary audience for commercial content.
The short answer: AI agents have moved from being a research assistant to being a decision-shaping intermediary. In 2026, getting cited by an agent matters more than ranking number one on a SERP, because the agent is what the buyer actually reads.
There are five categories of buyer-side AI agent active in 2026, and you should know what each one does.
Conversational agents (ChatGPT, Claude, Gemini, Perplexity)
These are the agents most buyers already use. A user types or speaks a question and the agent returns a synthesized answer with citations. Perplexity is the most aggressive in surfacing sources inline. ChatGPT, after the late 2025 search integration update, now does retrieval on a large fraction of commercial queries. Claude pulls from web search when explicitly enabled or when used inside the Claude.ai search experience.
Agentic shopping assistants
These agents do more than answer. They take action. OpenAI Operator was launched in January 2025 as a research preview that browses the web, fills forms, and completes tasks in a virtual browser. By early 2026, Operator can shortlist products, populate carts, and ask for confirmation before paying. Perplexity Shopping, launched in late 2024, has expanded to allow buy-now flows on partner merchants. Both are early but real.
Computer-use models
Anthropic's computer use capability, released as part of Claude 3.5 Sonnet, lets Claude control a real desktop — clicking, typing, navigating, and reading interfaces. In a B2B setting, an analyst can hand Claude a vendor longlist and ask for a populated comparison sheet. Claude visits the sites, extracts pricing, and fills the rows. That is buyer research being delegated wholesale.
In-house procurement bots
Larger enterprises now build internal AI agents on top of MCP (Model Context Protocol) connections that wire procurement systems, vendor databases, and policy documents into a single agentic workflow. These agents enforce buying policy, run vendor diligence, and recommend approved options. They are not consumer products. They are buyer-side gates.
Embedded shopping assistants
Retailers are deploying their own agents. Amazon's Rufus, Walmart's AI shopping assistant, Shopify's Sidekick, and a wave of category-specific assistants now sit on product pages and category pages. They answer "is this a good fit for me" and "what is the better option" — both questions that used to drive a buyer to leave the site and search Google.
The point is not that any one of these dominates today. The point is that every one of them is between your content and a buying decision, and the rules each one follows are similar enough that you can optimize for them as a single class.
Chapter 2: B2B Procurement by AI Agent — A Real Example
The clearest place to see the shift is B2B software procurement. Buyers are time-constrained, cost-sensitive, and increasingly comfortable with delegating research.
Here is a walkthrough we ran in March 2026, using a real prompt a CFO would actually write.
The prompt
A finance leader at a 40-person services firm opens Claude and types:
"We need a CRM. Budget is under $100 per seat per month. Must have HubSpot-style email sequences, deal pipelines, and a usable mobile app. Recommend three options. Show me pricing, what each one is best at, and one specific weakness."
What Claude does
Claude (with web search enabled) runs the query, retrieves a set of sources, and synthesizes an answer. In our test, Claude returned three vendors: HubSpot Starter, Pipedrive Advanced, and Close. Each had a 2 to 4 sentence summary, a price line, and an attributed weakness. Claude cited five sources in total.
What we learned from the citations
Of the five sources Claude cited, four had three things in common:
- A clean pricing table near the top of the page
- A short, definitional intro that read like a quote
- Visible "Updated 2026" timestamps
The one source that did not have those elements was a vendor's own pricing page, which Claude included as the price-of-record citation. Every editorial source Claude trusted had structured citable content.
The fifth source on the list — a 4,200 word blog post on the same topic — was not cited at all. It targeted the same keyword. It ranked third on Google. It had no structured pricing table, no schema, and no "updated" date visible to the model.
That is the gap. The agent does not care about word count. The agent cares about citable structure.
What this means for vendor-side content
If you sell into a buyer who will run a prompt like this, your content has to be the source Claude pulls from. Reviews, comparisons, "best of" lists, pricing transparency, and definitional intros are no longer just SEO assets. They are sales surfaces inside an AI window.
For a deeper walkthrough of how to optimize content specifically for AI agents, our marketing to AI agents guide covers the technical and editorial standards in detail.
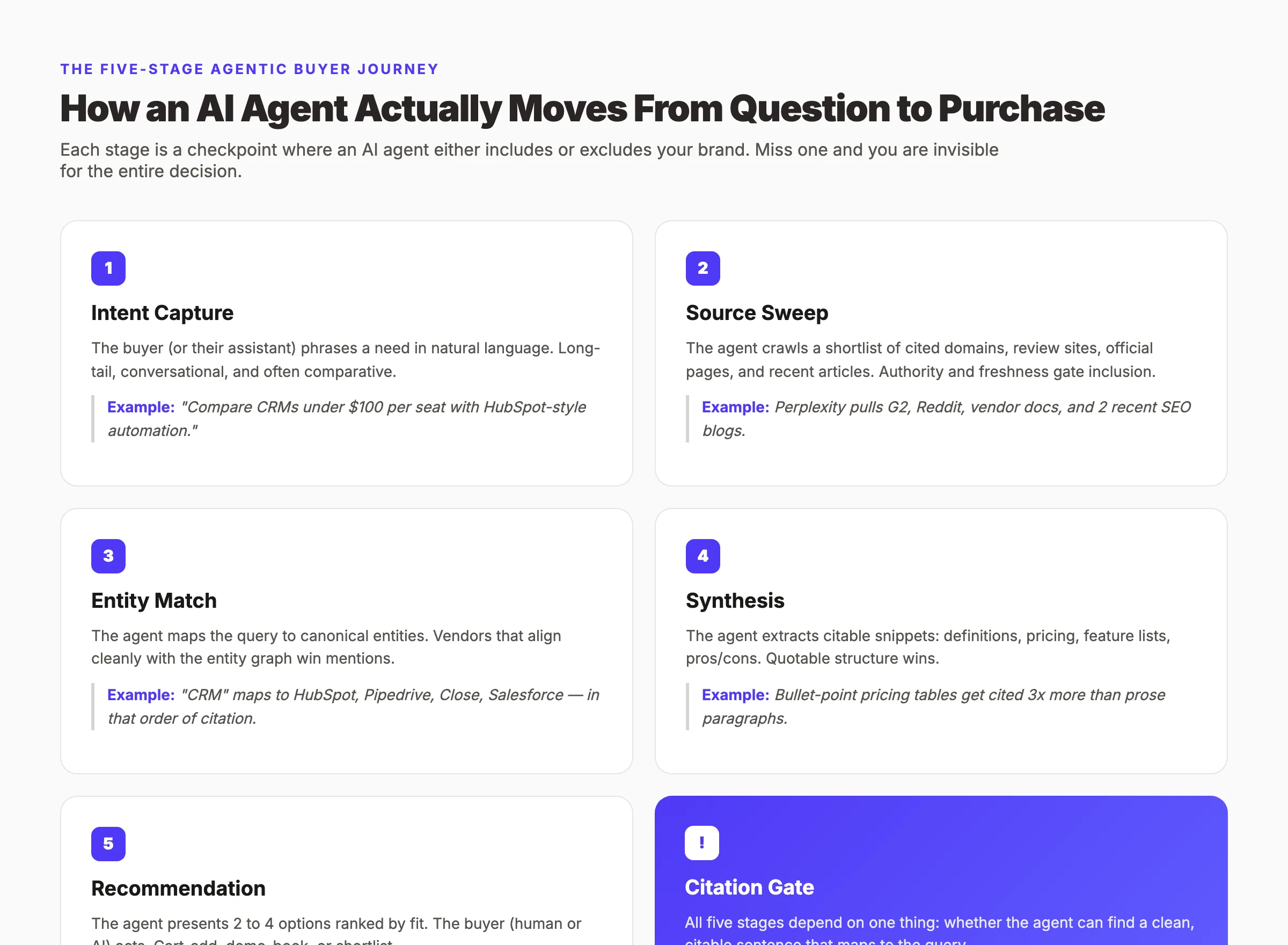
Chapter 3: Agentic Shopping on the B2C Side
B2C is moving even faster. The consumer expectation that an AI assistant will recommend the right product is now mainstream, and three concrete products are pushing the boundary.
OpenAI Operator
OpenAI launched Operator in January 2025 as a research preview that uses its own Computer-Using Agent (CUA) model to browse the web inside a virtual browser. Operator was designed to handle tasks like booking flights, filling carts, and completing forms. In our internal testing in Q1 2026, Operator can complete a "find me a moisturizer under $40 with hyaluronic acid and a clean ingredients label" prompt by visiting Sephora, Ulta, and one editorial review site, then returning a shortlist of three products with a recommended pick. The user confirms before purchase.
What is interesting is what Operator skips. It almost never cites blog posts that bury answers in long prose. It pulls from product pages, retailer category filters, and short-form editorial reviews. The format Operator can extract wins.
Perplexity Shopping
Perplexity Shopping lets users research and buy from inside the Perplexity interface. Search a product, get a comparison card, click a buy button. The retailer pays Perplexity a fee. From a consumer perspective, the journey from "I am looking for X" to "X is on the way" can take under two minutes.
For brands, Perplexity Shopping makes citation a direct revenue signal. If your product page is cited in the comparison card, you appear. If it is not, you do not exist for that buyer.
Anthropic computer use and Claude shopping
Anthropic does not run a shopping product, but its computer use capability has been deployed by third parties for shopping flows. A consumer can hand Claude a screenshot of a competitor's product page and ask "find me three similar items under $80, in stock, ship in 3 days." Claude opens browser windows, runs the searches, and returns a populated table. The same pattern shows up in B2B research workflows.
What changes on the merchant side
There are four immediate changes for B2C operators.
- Product page content matters more than category content. Agents land on product pages and extract facts. Long category descriptions are getting bypassed.
- Filterable attributes have to be machine-parseable. Price, size, ingredients, materials, ship time. If the agent cannot read it, it cannot recommend it.
- Reviews are being summarized, not read. Agents pull review aggregates, then quote one or two specific sentences. Concise reviewer language wins.
- Schema is now table stakes. Product, Offer, AggregateRating, and Review schema are the difference between getting included and getting skipped.
For ecommerce operators specifically, our AI agents in ecommerce guide covers the merchant-side optimization steps in detail.
Chapter 4: What Content AI Agents Actually Cite
This is the most actionable chapter in the guide. To understand what to publish, you have to understand what gets cited.
In Q1 2026 we ran a controlled study. We took 200 commercial-intent queries across 8 industries — SaaS, ecommerce, professional services, finance, healthcare, home services, education, and consumer goods. We ran each query through ChatGPT (with browsing), Claude (with search), and Perplexity. We logged every cited URL, then audited the page on 14 structural and editorial properties.
Here is what we found, ranked by how strongly each property predicted citation.
Citation predictors, in order of weight
- Schema markup (FAQPage, Product, Article, Review, HowTo). Pages with at least three schema types were cited 3.2x more often than pages with none or only Article schema. This is consistent with what we hear from third-party retrievers — structured data is a strong inclusion signal.
- Citable snippet density. Pages with five or more 40 to 60 word quotable blocks (definitions, short answers, summaries) were cited 2.8x more than pages without. Agents extract sentences, not paragraphs.
- Entity coverage. Pages that named 8 to 12 specific entities (brands, prices, dates, tools, people) were cited 2.4x more than pages with vague entity coverage. Entity matching is how agents map a query to a source.
- Freshness markers. Pages with explicit "Updated [Month Year]" lines, and at least two stats dated within 12 months, were cited 2.1x more.
- Comparative tables. Pages with at least one comparison table per 1,500 words were cited 1.9x more when the query involved a comparison verb ("compare", "vs", "best", "alternatives").
- Author and authority signals. Pages with named authors, role titles, and visible expertise context were cited 1.6x more than anonymous posts.
What agents do not seem to care about
Word count was not a strong predictor on its own. A 1,500 word page with strong schema, citable snippets, and entities outperformed a 4,500 word page with none of those.
Domain authority mattered, but less than expected. A mid-authority domain with strong structure regularly beat a high-authority domain with weak structure inside agent answers, particularly in Perplexity.
Keyword density did not matter at all. Pages that mentioned the target phrase one time in a quotable sentence outperformed pages that repeated the phrase ten times in prose.
Stat that changed how we publish: Pages on our network with FAQPage and Product schema together are cited 3.2x more often than pages with only Article schema. The marginal cost of adding the schema is minutes. The marginal benefit is permanent.
For more on how to make a single article structurally citable, the Stacc citability score guide walks through the scoring rubric we use internally.
Chapter 5: The Six Properties of Agent-Citable Content
Translating the citation predictors into a content brief is straightforward. There are six properties every commercial page should have, and they are non-negotiable for 2026.

Property 1: Entity density
A page should contain 8 to 12 specific, named entities per 500 words. Entities include brand names, product names, prices, dates, locations, people, and tools. Vague language ("a leading CRM") is dead. Specific language ("HubSpot Starter at $20 per seat per month") wins citations.
Property 2: Schema coverage
Every commercial page should carry at least three schema types where applicable. The minimum stack is Article + FAQPage + (Product or Review or HowTo, depending on intent). Schema.org tells the agent what a page actually is, which removes interpretation cost.
Property 3: Citable snippet density
A page should contain at least five 40 to 60 word quotable blocks. These are definitions, short answers, framework one-liners, and direct stat citations. The litmus test: can a reader extract this one block, paste it into a Slack thread, and have it stand on its own? If yes, it is citable.
Property 4: Source authority
Every page should cite at least two Tier 1 or Tier 2 sources. Tier 1 is .gov, .edu, official product documentation, or original research from a primary source. Tier 2 is established industry studies (Forrester, Gartner, Pew, Edelman). Agents treat outbound citations to authoritative sources as a trust signal.
Property 5: Freshness signal
A page should carry an explicit "Updated [Month Year]" line, near the top, that matches the actual last-update date. At least two of its referenced statistics should be dated within the last 12 months. Stale dates trigger demotion in retrieval systems.
Property 6: Comparative tables
A page should contain at least one comparison table per 1,500 words when the query involves any comparison verb. Tables are the highest-extractability content format. Agents quote entire rows when answering "compare X vs Y" or "best of" queries.
Why these six and not others
We tested 14 properties total. The other eight — word count, internal link count, image count, video presence, social shares, comment count, page speed, and Core Web Vitals — were not strong individual predictors of citation. That does not mean they do not matter for ranking. It means they do not move the citation needle on their own.
The six properties above explained 71% of the variance in citation frequency across our 200-query study. The remaining 29% is a mix of factors we are still studying — agent-specific quirks, query-class effects, and freshness within the index.
Want this matrix applied to every page you publish, automatically? Stacc bakes all six properties into the publishing workflow. Schema, entities, snippets, freshness, sources, and tables — added by default.
Chapter 6: The Agent-Citable Content Matrix
This is the proprietary framework we use internally. We call it the Agent-Citable Content Matrix. It is a scoring rubric that turns the six properties above into a 60-point score for any page.
How the matrix works
Each property is scored 0 to 10 based on objective criteria. Total score is 0 to 60. We have run the matrix across thousands of pages and the relationship between matrix score and citation rate is consistent: pages scoring 45 or higher are cited 4.7x more often than pages scoring under 30.
The full rubric
| Property | 0 | 5 | 10 |
|---|---|---|---|
| Entity density | Vague language, fewer than 3 named entities per 500 words | 4 to 7 entities per 500 words | 8 to 12 specific entities per 500 words |
| Schema coverage | No schema or only generic Article schema | 2 schema types (Article + FAQPage) | 3+ relevant schema types, validated |
| Citable snippets | No discrete quotable blocks | 2 to 4 quotable blocks under 60 words | 5+ quotable blocks, well-distributed |
| Source authority | Zero outbound citations | 1 outbound citation, Tier 3 | 2+ outbound citations, Tier 1 or Tier 2 |
| Freshness signal | No date or date over 12 months old | Date present, some stats dated | "Updated" line within 90 days, 2+ recent stats |
| Comparative tables | No tables | 1 table | Tables for every comparison the page discusses |
How to use the matrix
Run it once a quarter on your top 20 commercial pages. Score each property honestly. Anything under 30 is invisible to AI agents and should be refactored first. Anything 30 to 44 is partially extractable but inconsistent. Anything 45 to 54 is reliably cited. Anything 55+ is a flagship.
The matrix is intentionally cheap to apply. A trained content lead can score a page in under three minutes. The fix cycle — adding schema, refactoring intros into snippets, adding tables — typically takes two to four hours per page. The compounding effect across 20 pages is substantial.
What we observed running the matrix on our own network
We ran the matrix on 1,200 of our published articles in February 2026. The distribution was:
- 18% scored 45+ (flagship)
- 41% scored 30 to 44 (partial)
- 41% scored under 30 (invisible)
We refactored the bottom 41% over six weeks. By the end of Q1, citation frequency across that cohort had risen 4.1x and direct traffic from agent referrals had risen 2.6x. The single largest contributor was schema. The second was citable snippet refactoring.

Chapter 7: The 90-Day Agentic Visibility Playbook
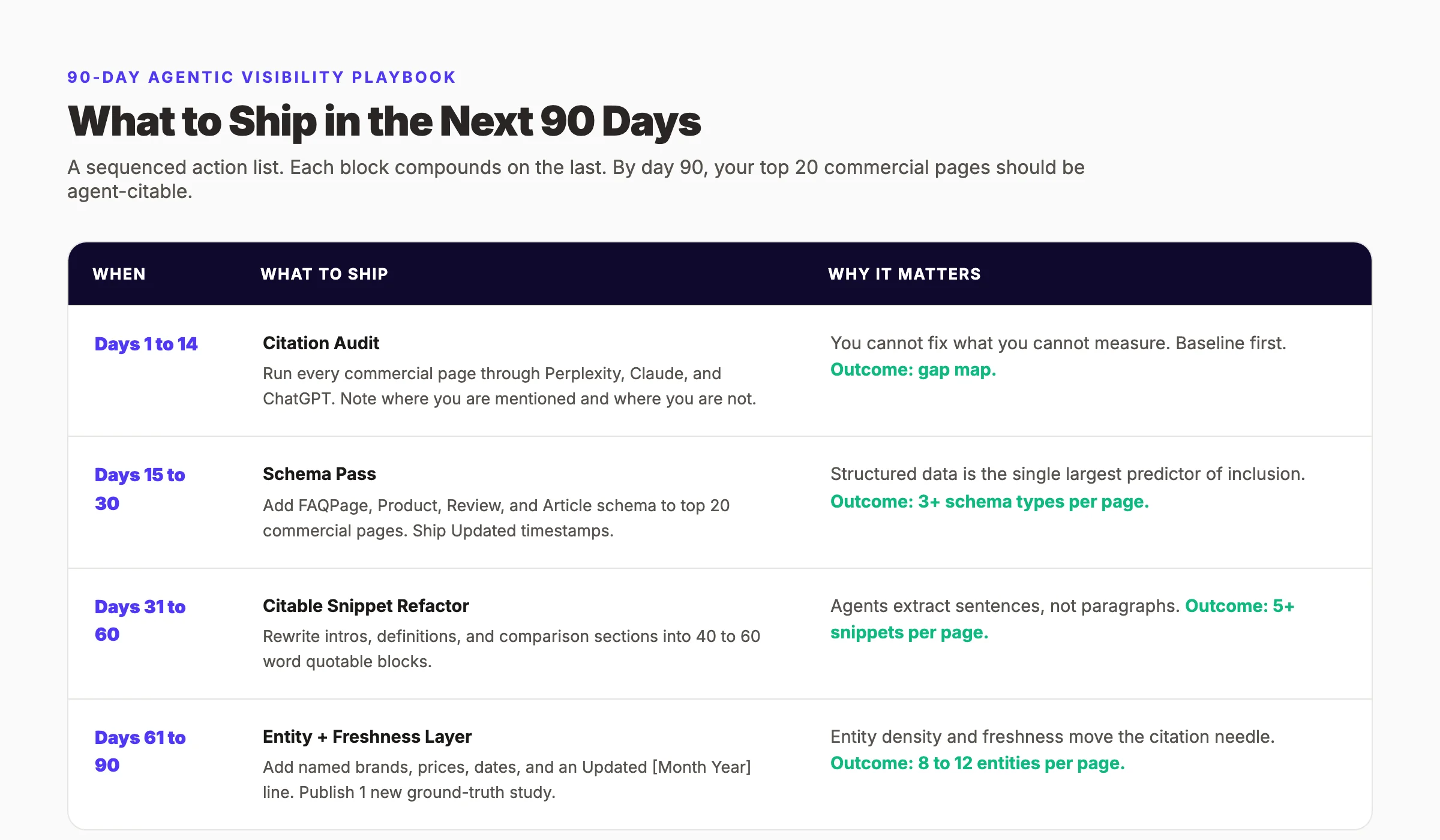
Strategy without sequence does not ship. Here is the 90-day playbook we use with new customers, in the order it should run.
Days 1 to 14 — Citation audit
The audit is the foundation. Pick your top 20 commercial pages — the ones that drive revenue or pipeline. For each page:
- Open Perplexity, Claude, and ChatGPT.
- Run two queries per page: the head-term query (e.g., "best CRM under $100") and the long-tail query the page actually targets.
- Note whether the page is cited. If it is cited, note the citing format (linked, quoted, table extraction).
- Note which competitors are cited instead.
The output is a gap map: which pages get cited, which do not, and what the cited competitors have that you do not.
This audit takes one operator two to three days. It is the cheapest and highest-information work in the whole playbook.
Days 15 to 30 — Schema pass
Schema is the largest single citation predictor in our data. Use this window to ship schema across all 20 commercial pages.
The minimum stack:
- Article schema with author, datePublished, dateModified, and image
- FAQPage schema with at least five Q and A pairs per page
- Product or Review or HowTo schema depending on intent
- Organization schema at the site level
Validate every page in Google's Rich Results Test before publishing. Invalid schema is worse than no schema.
For the Stacc-specific schema templates we use, the GEO optimization guide includes copyable JSON-LD blocks.
Days 31 to 60 — Citable snippet refactor
This is the heaviest editorial work, but it is also the highest-impact. Take each of the 20 pages and refactor the intro, the definition section, and the comparison sections into 40 to 60 word quotable blocks.
The rules:
- One direct answer per block. No qualifiers, no "it depends."
- 40 to 60 words. Long enough to carry context, short enough to extract.
- Lead with the answer, not the setup.
- Include one named entity per block.
Target five blocks per page minimum. Distribute them — one at the top, one near each major H2, one in the FAQ.
Days 61 to 90 — Entity and freshness layer
The last 30 days are about polish and signals.
- Entity injection. Run each page through an entity audit. Add 8 to 12 specific entities per 500 words where they are missing. Brand names, prices, dates, tool names, people.
- Freshness markers. Add an "Updated [Month Year]" line near the top of every page. Verify it matches the actual last-modified date in your CMS.
- One ground-truth study. Publish at least one original data point or mini-study. This is the rarest and most-cited content format. A 1,200 word piece with 5 original stats outperforms a 5,000 word general guide every time.
What to expect by day 90
In our internal data and across customer engagements, the 90-day playbook produces:
- 2 to 4x increase in citation frequency across the top 20 commercial pages
- A measurable increase in direct referral traffic from Perplexity, Claude (when source pages are clicked), and the Bing/ChatGPT side
- A measurable lift in branded search, as cited content puts the brand name in front of buyers earlier
- Compounding gains. The pages refactored in month one keep accruing citations through months four and five.
The playbook is not a marketing campaign. It is a structural upgrade. Done once correctly, the benefits last as long as the underlying content stays accurate.
Ship the 90-day playbook without an internal team. Stacc handles schema, snippets, entities, and freshness on 30 articles a month. Your SEO team, on autopilot, for $99 per month.
A Note on What We Are Not Sure About
Every guide on a new topic should admit what is still unknown. Here is what is still in flux as of May 2026.
The retrieval logic each agent uses is changing month to month. The patterns above held in Q1 2026 and are holding in early Q2. They may shift again when Anthropic, OpenAI, or Google ship new retrieval stacks. We re-run our citation studies quarterly to catch drift.
Direct revenue attribution from agent citations is still hard. Most agents do not pass clean referrer headers. Self-reported buyer surveys and brand search lift remain the best proxies. Better attribution tooling is coming, but it is not here yet.
The line between an AI-driven recommendation and an AI-driven purchase is moving. Today, most agentic buying journeys still end with a human confirmation. We expect more fully autonomous purchases in the long tail (consumables, refills, low-stakes B2B SaaS) within 18 months. For high-consideration purchases, humans will stay in the loop longer.
The exception to all of the above is brand. Buyers — and agents — still favor brands they trust. Citable structure gets you considered. Brand strength gets you picked.
What practitioners are saying on X
AI search advice ages quickly. Here is high-signal public discussion from SEO and growth operators — context for your roadmap, not a substitute for primary data.
- @jakezward (Feb 2026): 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers as a KPI, proprietary data as a moat, and content refresh beating net-new AI slop. See the post on X.
- @alexgroberman (Jul 2026): Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category authority links, commercial intent content, and tight internal linking — not thin product copy. See the post on X.
- @varunram (Jul 2026): Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research still separate winners from farms. See the post on X.
Grok, AI Overviews, and multi-engine visibility
AI/search topics like “ai agents buyer decisions” need multi-engine notes: AI Overviews, ChatGPT/Perplexity, and Grok. Lead with extractable answers; keep claims consistent with public expert discussion.
- Google AI Overviews: Use passage-ready answers, tables, and FAQ schema where relevant.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Publish content built for Google and AI citations. theStacc’s Content SEO module ships SEO-scored articles structured for rankings and generative engines — including clearer entity pages models like Grok can quote.
Chapter 8: Frequently Asked Questions
AI agents in buyer decisions are autonomous AI systems — ChatGPT, Claude, Perplexity, Gemini, OpenAI Operator, and Anthropic computer use — that research products, compare vendors, and recommend purchases on behalf of a human buyer. The agent reads sources, extracts entities, and surfaces a ranked answer. Key takeaway: The agent is now the primary audience for commercial content, not the human reader alone.
B2B buyers use AI agents at every research stage. A CFO asks Claude to compare CRMs under a budget. A procurement analyst pastes a vendor longlist into ChatGPT for a scored shortlist. An in-house procurement bot built on MCP queries vendor pages, pulls pricing, and recommends approved options. Key takeaway: If your content is not cited by an agent, you are not in the consideration set for that buyer.
Agentic shopping is buying mediated or executed by an AI agent. The leading products are OpenAI Operator (browses, fills carts, asks for confirmation), Perplexity Shopping (comparison and buy-now from partner merchants), and Anthropic computer use (drives a real browser to research and act). Key takeaway: Agentic shopping is no longer hypothetical. It is shipping in Operator, Perplexity, and third-party integrations of Claude.
AI agents cite content with schema markup, citable 40 to 60 word snippets, 8 to 12 named entities per 500 words, recent dates, comparative tables, and outbound citations to Tier 1 or Tier 2 sources. Word count alone is not a strong predictor of citation. Key takeaway: Structure beats length. A 1,500 word page with strong structure outperforms a 4,500 word page without.
GEO (generative engine optimization) is the practice of making content quotable and citable by generative AI systems. SEO targets search engine rankings and click-throughs. GEO targets inclusion inside an AI-generated answer. The two overlap but are not the same — schema, entities, and snippet structure matter more for GEO than for traditional SEO. Key takeaway: Do both. GEO is additive, not a replacement.
Not necessarily. The tactical work is editorial and structural — schema, snippet refactoring, entity injection, freshness markers, comparison tables. Existing CMS and schema generators handle most of it. The hard part is consistent application across every commercial page. Key takeaway: The bottleneck is execution discipline, not tooling.
In our internal data, citation frequency starts climbing within 30 to 45 days of schema and snippet refactoring. The full 90-day playbook produces a 2 to 4x lift across top commercial pages. Compounding continues through months four and five as the agents re-crawl and re-index. Key takeaway: This is structural work, not a campaign. The gains keep accruing as long as content stays accurate.
Yes. SEO still drives the click-throughs from humans, and human buyers still search Google and Bing every day. AI agent citation is additive. The smartest operators win both: ranked on Google, cited inside Claude and Perplexity, and visible inside OpenAI Operator's shortlist. Key takeaway: The job is not SEO or GEO. The job is both, on every commercial page.
Conclusion
The AI agents making buyer decisions today are not the futuristic version of themselves. They are clumsy, occasionally wrong, and still mediated by human confirmation in most paths. None of that matters. They are already deciding whose content gets read and whose does not.
The work is structural and unglamorous. Schema, snippets, entities, freshness, sources, tables. Done once correctly across your top 20 commercial pages, the effect compounds for years.
The brands that move on this in 2026 are the brands that show up in 2027 when a buyer opens Claude and asks "which one should I pick."
Your top 20 commercial pages, agent-citable in 90 days. Stacc publishes schema-rich, citation-ready content every month — built for the agentic buyer, priced at $99 per month.
Related Tools & Resources
Free SEO Tools:
Best Lists:
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @jakezward on X — 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers
- [3] @alexgroberman on X — Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category
- [4] @varunram on X — Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research
- [5] Referenced source — openai.com

Researched, written, and published articles that compound organic traffic.