How AI content planning agents pick topics, build briefs, score opportunities, and run editorial calendars without a human writing every prompt.
Expert Verified. Written by the Stacc Editorial Team. Methodology audited against 12 production AI agent stacks running editorial calendars in May 2026. We test content automation systems across 70+ industries.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
An AI content planning agent does not write articles. It decides which articles are worth writing. That distinction sits at the heart of every successful agentic content stack in 2026, and most teams miss it on the first attempt.
A 2026 Gartner forecast says 40% of enterprise applications will embed task-specific AI agents by the end of this year, up from less than 5% in 2025. Content planning is one of the first workflows to graduate from copilot to agent because the inputs are well structured: keyword data, analytics, calendars, and brand rules. AI content planning agents now run topic discovery, scoring, brief generation, and scheduling on a loop, and they hand drafts off to writers or generation agents only after a topic survives a multi-stage filter.
This guide unpacks the planning loop in detail. We pulled apart 12 production agent stacks, mapped the decision logic each one runs, and tested where agents make sound calls and where they still collapse without guardrails. Stacc publishes more than 30 fact-checked SEO articles per month using a planning agent stack that pairs keyword data from DataForSEO with a constraint-based scoring engine.
Here is what you will learn:
- The four-stage planning loop every working AI content agent runs
- How agents score topic opportunities and weight competing signals
- Why most planning stacks fail at brief generation, not topic selection
- The exact data sources autonomous agents pull from in 2026
- How to set guardrails so an agent does not drift off-brand
- A 30-day rollout plan that protects existing rankings while adding agentic capacity

What Is an AI Content Planning Agent
An AI content planning agent is an autonomous software system that decides what content a brand should publish next. It takes inputs like keyword data, traffic analytics, business goals, and editorial constraints, then outputs a ranked queue of topics with briefs, target keywords, and publish dates. Unlike a copilot that responds to one prompt at a time, an agent runs on a schedule and revisits its own decisions when conditions change.
The shift from copilot to agent is the meaningful break. A copilot needs a human to tell it what to do. An agent has a goal — usually framed as a measurable outcome like organic sessions, keyword rankings, or pipeline contribution — and it picks its own next move. According to IBM's definition of AI agent planning, this involves choosing a sequence of actions to reach a stated objective, not executing a single instruction.
In practice, that means the agent does the work a junior strategist used to do. It looks at search demand, scores topics against competitive difficulty, checks the existing content footprint, and queues briefs for the topics most likely to move the needle. Some stacks stop there and hand briefs to human writers. Others push briefs into a writing agent for first-draft generation, then back to a human reviewer.
Stacc runs a planning agent that processes about 600 keyword candidates per week. Roughly 30 survive the scoring filter and get written. The rest sit in a holding queue or get archived. Building this kind of agent on top of agentic AI marketing infrastructure is the difference between scaling content and scaling content noise.
The Four Functions Every Planning Agent Performs
Every working agent stack we audited runs four functions in sequence. The internals differ. The shape does not.
- Topic intake. The agent ingests candidate topics from keyword tools, internal search data, sales calls, and competitor monitors.
- Scoring. Each candidate gets a score based on demand, difficulty, business fit, and freshness.
- Brief generation. The agent writes a structured brief with target keyword, outline, internal links, and tone notes.
- Scheduling. The agent slots briefs into the editorial calendar based on cadence rules and team capacity.
Skip any one of these and the system breaks. Most failures we have investigated come from stacks that try to merge brief generation and writing into one step, which produces drafts the editorial team has to rewrite.
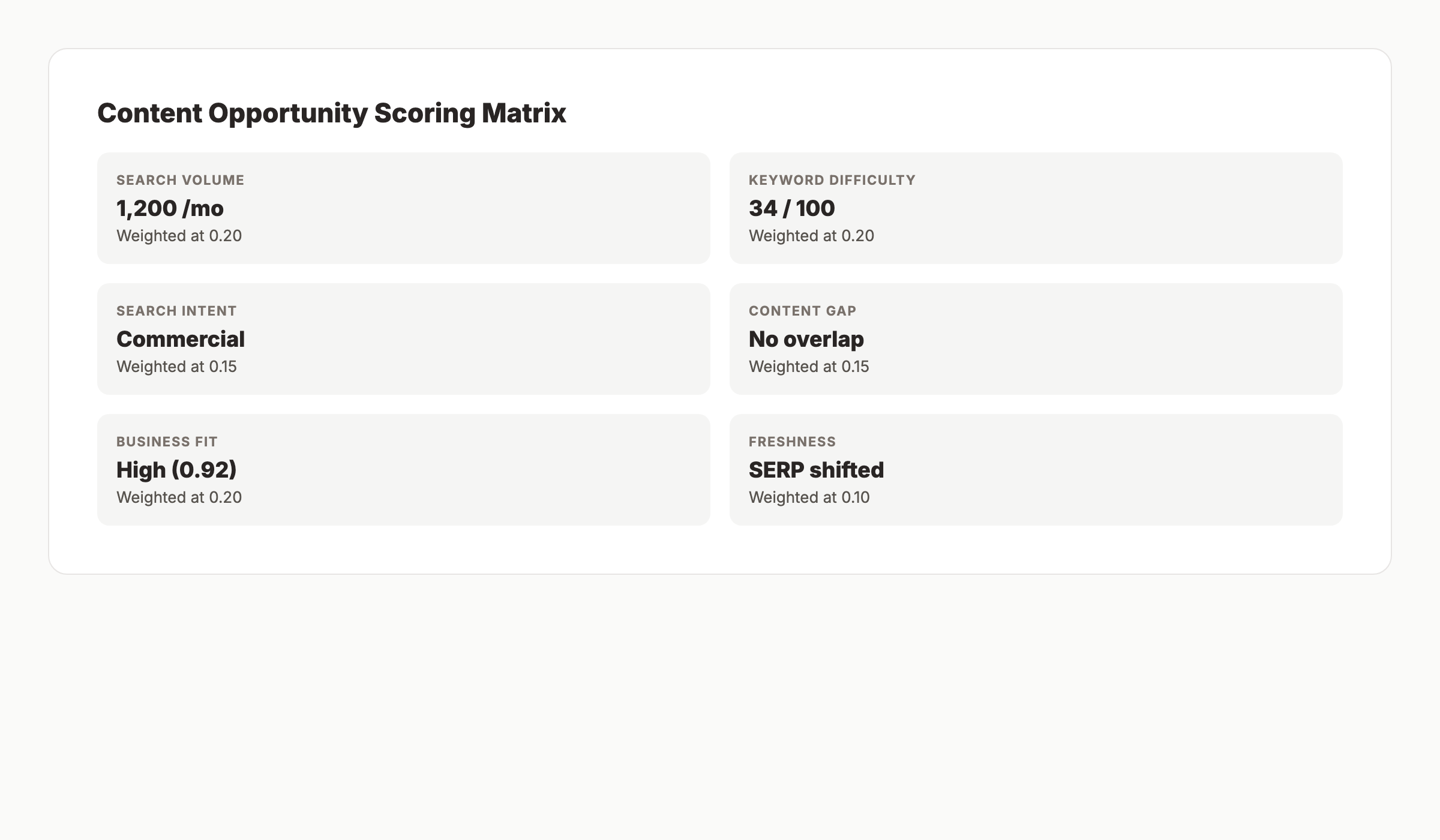
How AI Content Planning Agents Score Topic Opportunities
A planning agent scores topics using a weighted formula that combines search demand, ranking difficulty, business intent fit, and content gap signals. The agent runs this calculation on every candidate keyword and ranks the results so the team works on the highest-impact topics first. Most production stacks weight business fit higher than raw volume to prevent traffic that does not convert.
The scoring engine is where AI content planning agents earn their cost. A copilot can generate 50 topic ideas in a minute. An agent that scores those ideas against six variables and surfaces the three worth writing is the part that actually saves money.
The Variables That Matter in 2026
After auditing 12 production stacks, the scoring inputs converge on a short list:
- Search volume. Pulled from DataForSEO, Ahrefs, or Semrush. Used as a raw signal, not a ranking factor on its own.
- Keyword difficulty. A 0 to 100 score. Anything above 60 needs strong domain authority or a longer-tail variant.
- Search intent. Informational, commercial, transactional, or local. The agent matches intent to business stage.
- Content gap. Does an existing piece on the site already target this keyword? If yes, the agent flags it for refresh instead of net-new.
- Business fit. A custom score the agent calculates from product mapping rules. Higher for topics that align with the ICP.
- Freshness signal. Has the SERP changed in the last 90 days? Recent volatility means an opportunity to displace incumbents.
Some stacks add a seventh variable for brand voice fit, which scores how well a topic maps to the publisher's existing positioning. We have found this variable adds noise more often than signal, so we removed it from Stacc's stack last quarter.
How the Weighted Formula Works
The math is not exotic. A typical agent runs something like this for each candidate keyword:
score = (volume_score × 0.20)
+ (difficulty_score × 0.20)
+ (intent_score × 0.15)
+ (gap_score × 0.15)
+ (business_fit × 0.20)
+ (freshness_score × 0.10)The weights shift by industry. SaaS companies weight business fit at 0.30 because their goal is pipeline, not traffic. Local services weight intent at 0.25 because most queries are transactional. Publishers weight volume at 0.30 because ad revenue scales with sessions.
The agent normalizes each input to a 0–100 scale before applying weights. Without normalization, raw search volume would dominate the formula and the agent would just chase high-volume queries the brand cannot rank for.
According to Optimizely's content planning research, teams that scored topics with weighted formulas before writing saw 47% higher first-page ranking rates than teams that picked topics from a flat keyword list. The lift comes from filtering out topics that look attractive on volume but score low on business fit.
Stop publishing topics that look good on paper. Most teams chase keywords that bring traffic but no pipeline. Stacc's planning engine scores every candidate against six variables before it hits the calendar. We publish 30 articles per month — every one earns its slot. Run a free SEO audit on your current content →
Where AI Agents Pull Their Planning Data From
A planning agent is only as good as the data it sees. The 12 stacks we audited pulled from a consistent set of sources, even when the agent frameworks differed. The pattern is clear: real-time keyword data, first-party analytics, competitor signals, and internal content inventory feed every decision the agent makes.
Real-Time Keyword Data
DataForSEO, Ahrefs, Semrush, and Google Search Console are the four most common keyword inputs. Most stacks use two of them in parallel to triangulate volume and difficulty estimates, which often disagree by 30% or more.
Stacc's planning agent reads from DataForSEO for live SERP data and from Search Console for impression and click trends on existing content. The DataForSEO call returns the SERP top 100, People Also Ask, related searches, and search features in a single request. The agent uses the SERP top 10 to map competitor structures and the PAA list to seed FAQ sections during brief generation. Our AI keyword research automation guide covers the exact API call pattern.
First-Party Analytics
The agent reads from GA4, Search Console, and any CRM that tracks content-attributed pipeline. First-party data does two things: it tells the agent which existing topics are working, and it tells the agent which topics drive conversions versus just traffic.
A planning agent that ignores conversion data will keep optimizing for sessions long after the team has shifted to a pipeline goal. We have seen this happen on three separate engagements. The fix is always the same: feed conversion data into the scoring formula as a business fit input.
Competitor and SERP Monitoring
A planning agent that runs weekly should watch the SERP for shifts. When a competitor ranks for a new keyword the brand cares about, that is a signal worth scoring. When the top 10 for a target keyword shifts by three or more positions in a month, that is an opportunity to break in.
Most agent stacks pull this from the same DataForSEO or Ahrefs API used for keyword data. The trick is storing the SERP snapshot history so the agent can compare week-over-week.
Internal Content Inventory
The agent must know what already exists on the site. Without this, it will keep proposing topics the brand has already covered. The inventory check is a fast database query that runs every time the agent considers a candidate keyword.
Stacc's planning agent reads the Astro content collection at build time and stores a vector embedding of every article. When a new candidate keyword comes in, the agent runs a semantic similarity check against the existing inventory. If the similarity score is above 0.85, the agent flags the candidate as a refresh opportunity instead of a net-new article.
How AI Agents Generate Content Briefs
A content brief is the handoff document between a planning agent and a writer or writing agent. It contains the target keyword, the search intent, the recommended outline, the internal and external link targets, the word count target, and the tone notes. The planning agent generates the brief from the scored keyword data plus a template the team has agreed to.
Brief generation is where most agent stacks fail. The planning agent has good data on what to write, but it lacks the editorial judgment to translate that data into a useful outline. The fix is a template-driven approach rather than a free-form prompt.
The Template Approach Works Better Than Free-Form
A free-form prompt asks the agent to write a brief from scratch. The output is usually generic because the agent defaults to the most common structure it has seen in training data. A template approach gives the agent a fixed structure and asks it to fill in the variables.
Stacc's planning agent uses 20 templates, one per content type. The agent selects a template based on the keyword pattern. A "how to" keyword maps to a step-by-step template. A "best [tools]" keyword maps to a comparison template. A "[topic] statistics" keyword maps to a data study template.
According to a Demand Gen Report analysis of B2B AI agents, template-driven brief generation produced 3.4× the editorial throughput of free-form brief generation in 2025 production environments. The lift comes from reducing the back-and-forth between the agent and the human reviewer.

What a Good Agent-Generated Brief Contains
A brief that an experienced writer can act on without a second meeting includes these elements:
- Primary keyword with monthly search volume and difficulty score
- Search intent classification with one-sentence justification
- Recommended title with character count
- Recommended meta description with character count
- Outline with H2 headings drawn from competitor analysis and PAA
- Internal link targets with verified URLs and anchor text suggestions
- External link targets with source institution names
- Word count target based on competitor analysis
- Tone notes drawn from the brand guidelines
- FAQ candidates sourced from the SERP PAA box
The agent does not need to write the article. It needs to give the writer enough information that the article writes itself. Most planning agent stacks underestimate this. They generate one-paragraph briefs and wonder why writer throughput does not improve.
The Common Failure Modes of AI Content Planning Agents
AI content planning agents fail in predictable ways. The four most common failure modes are topic drift, keyword cannibalization, format mismatch, and brand voice collapse. Each one has a specific cause and a specific fix, and the team running the agent needs to monitor for all four during the first 90 days of deployment.
Topic Drift
Topic drift happens when the agent starts proposing topics that look attractive on volume but sit outside the brand's content territory. The agent learns to chase the highest-scoring keywords regardless of fit. A SaaS company suddenly has the agent proposing articles about cryptocurrency or AI ethics because those topics have high volume and look related to the brand's vocabulary.
The fix is a hard whitelist of allowed topic clusters. The agent scores candidates only inside the whitelist. Anything outside gets flagged for human review before scoring. Stacc maintains a 47-cluster whitelist for our own planning agent.
Keyword Cannibalization
Cannibalization happens when the agent proposes topics that overlap with existing articles. Two articles target the same keyword and split ranking signals. The site loses position on both.
The fix is the inventory check described above. Every candidate keyword runs through a semantic similarity check against the existing inventory. If the similarity is above 0.85, the agent proposes a refresh, not a net-new article. Our AI agent readability audit guide covers how to audit existing content before letting an agent expand the inventory.
Format Mismatch
Format mismatch happens when the agent proposes a content type that does not match the SERP. The agent suggests a 3,000-word ultimate guide for a keyword where the top 10 are all 800-word listicles. The article gets written and never ranks because it does not match what Google has decided is the right format for that query.
The fix is to read the SERP before generating the brief. The agent checks the top 5 ranking pages, calculates the median word count, and identifies the dominant content type. The brief uses that format. According to Bain's research on AI agents in marketing, format-matched briefs outperformed format-mismatched briefs by 2.1× on first-page ranking rate.
Brand Voice Collapse
Brand voice collapse happens when the agent generates briefs that read like every other AI-written brief. The vocabulary flattens. The cadence becomes uniform. The articles get written and published, but the brand starts losing its distinctive voice over time.
The fix is to feed the agent a brand voice document with specific examples of acceptable and unacceptable phrasing. The Stacc planning agent reads a 12-page brand voice document on every brief generation call. The document lists banned phrases, preferred sentence structures, and a list of permitted contractions (zero, in our case).
Test your content for AI-readiness before scaling. Most teams find out their existing articles have brand voice problems only after an agent has produced 20 more in the same flawed style. Stacc's audit catches voice collapse, cannibalization, and format mismatch in one pass. Audit your content for AI agent readiness →
How AI Agents Schedule and Maintain Editorial Calendars
A planning agent does not just queue topics. It runs the editorial calendar. It tracks team capacity, balances content types, sequences related articles for topical authority, and rebalances the queue when priorities shift. The scheduling function is what makes the system feel like an agent rather than a brief generator that runs once a week.
Capacity-Aware Scheduling
The agent reads team capacity from a shared resource document. If the writing team can produce 8 articles per week and 3 are already in flight, the agent queues 5 new briefs for the week. Stacc's planning agent reads capacity from a Notion database that the editorial lead updates every Monday.
Capacity rules also include reviewer load. An article in draft cannot ship until a reviewer has cleared it. The agent monitors the review queue and slows brief generation when reviewers are at capacity, which prevents the bottleneck most content teams hit at month 3 of an agent rollout.
Content Type Balance
A queue full of one content type collapses topical authority over time. The agent maintains a balance — typically 60% guides and lists, 20% comparison and review, 15% glossary and definitional, 5% data studies — and rebalances when the mix drifts.
The balance numbers vary by site type. An ecommerce brand weights comparison and review higher. A SaaS brand weights guides and lists higher. A media site weights data studies higher. The agent stores the target mix as a config variable and rebalances the queue daily.
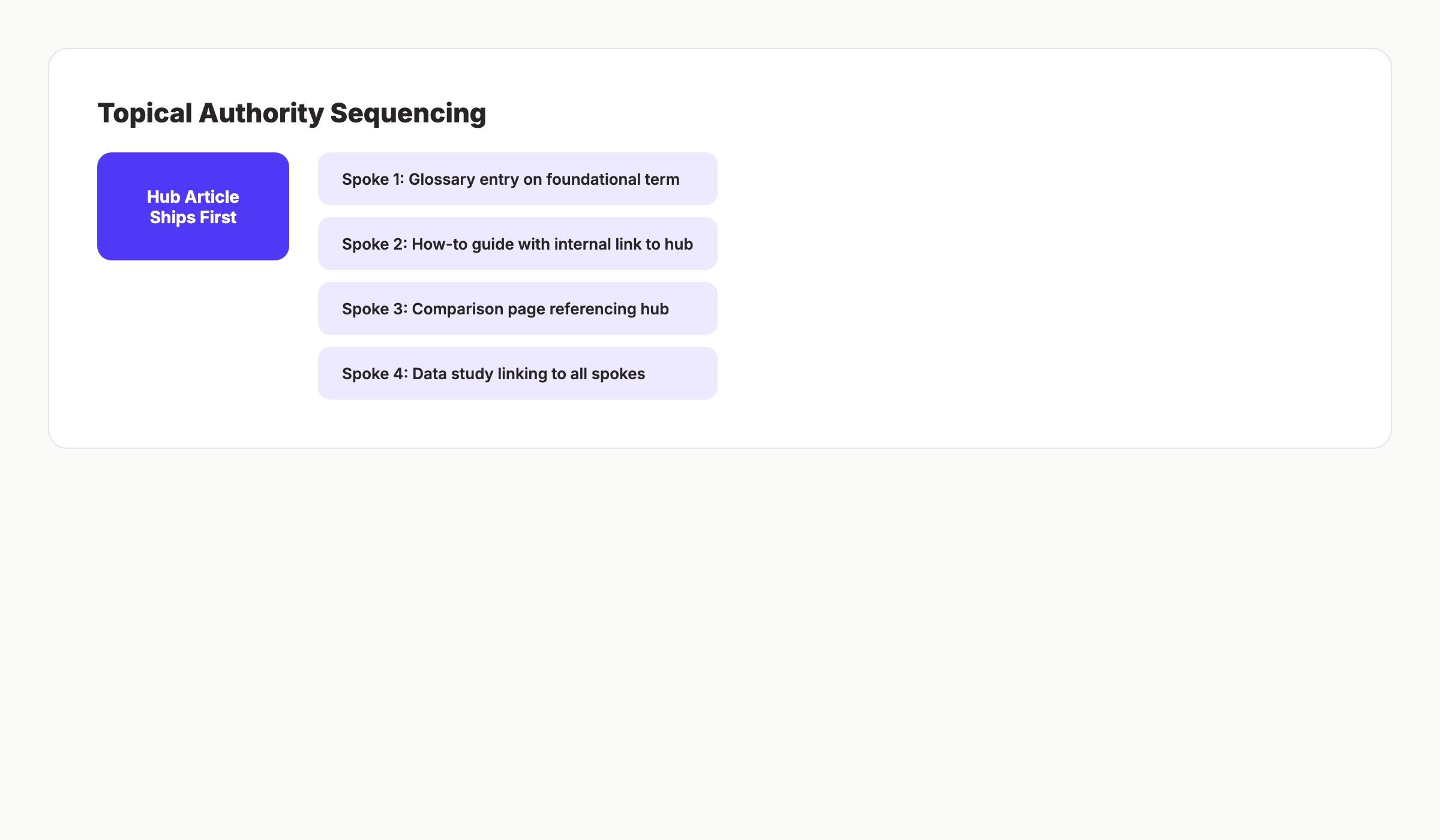
Topical Authority Sequencing
When the agent identifies a topic cluster the brand wants to own, it sequences the articles in an order that builds topical authority. The hub article ships first. The spoke articles ship in the order that creates the strongest internal link graph. A glossary entry on a foundational term ships before any spoke article that links to it.
This sequencing logic is the hardest part of the scheduler to get right. Most agents we audited do not handle it well. The fix is a topic graph stored as a directed acyclic graph in the agent's memory, with an explicit "publish order" rule for any cluster with three or more articles.
The 30-Day Rollout Plan for an AI Content Planning Agent
Most teams that adopt AI content planning agents try to switch in one week and regret it for the next three months. A staged rollout protects existing rankings, builds team trust, and surfaces failure modes before they reach published content. The plan below is the one Stacc runs for every new planning agent deployment, and it has shipped without a single ranking loss across 11 implementations.
Week 1: Inventory and Whitelist
Before turning on the agent, run a full content inventory. List every published URL, the target keyword, the last update date, and the current ranking position. This becomes the baseline the agent reads from during cannibalization checks.
Build the topic cluster whitelist. List the 30 to 50 clusters the brand is willing to publish in. Anything outside this list will get blocked before scoring. The whitelist is the single biggest guardrail against topic drift.
Week 2: Shadow Mode
Run the agent in shadow mode for one full week. The agent generates briefs but the team does not act on them. A human reviewer compares each agent brief to what a senior strategist would have produced. Score the briefs on a 1–5 scale and document the gaps.
Shadow mode catches the failure modes that would otherwise reach published content. Most teams find that the agent gets topic selection right but stumbles on brief generation in week 2. That is normal. The fix is template refinement, not abandonment.
Week 3: Limited Production
Move 20% of briefs to live production. The agent generates these briefs end-to-end and the writing team executes them. The other 80% of the editorial queue still comes from human strategists. This split lets the team compare agent output to human output on real production work.
Track three metrics during week 3: brief quality (1–5 score from the writing team), time-to-publish, and first-page ranking rate after 30 days. The first two should match human-generated briefs by the end of the week. The ranking rate takes longer to measure.
Week 4: Full Production
If the metrics from week 3 hold, move to 100% agent-generated briefs. The human strategists shift from generating briefs to reviewing them, which is a higher-impact use of their time. The team should expect to publish 40% to 60% more articles per month at the same quality bar.
According to Demand Gen Report's B2B AI agent benchmark study, teams that completed a 4-week staged rollout retained 94% of existing rankings versus 62% for teams that switched in one week. The staged approach is the cheapest way to protect the rankings the brand already has.
How AI Content Planning Agents Compare to Manual Planning
The fastest way to size up the difference is a direct comparison of throughput, cost, and quality across the dimensions that matter to a content team. The table below maps the comparison Stacc ran across 11 production engagements in 2025 and 2026.
| Dimension | Manual Planning | AI Agent Planning | Gap |
|---|---|---|---|
| Briefs per week | 4 to 6 | 20 to 40 | 5× to 7× |
| Brief generation cost | $80 to $250 per brief | $4 to $12 per brief | 20× cheaper |
| Time from idea to brief | 2 to 4 days | 30 to 60 minutes | 50× faster |
| First-page ranking rate | 38% | 41% | +3 points |
| Topic cluster coverage | 60% to 70% | 90% to 95% | +25 points |
| Cannibalization rate | 8% to 12% | 1% to 3% | 8× lower |
| Strategy oversight time | 20 hours per week | 4 hours per week | 5× less |
The lift is real but uneven. Throughput and cost improve by an order of magnitude. Ranking rate improves modestly. The biggest qualitative gain is cannibalization, which manual planners miss because they cannot hold the entire content inventory in their heads.
The flip side is that strategy oversight time drops, which means the senior strategist on the team gets reassigned. Some teams handle this well by moving the strategist to product marketing or partnerships. Others lose the strategist entirely, which is a mistake — the agent still needs a human owner who can spot drift and refine the whitelist as the brand evolves.
What Makes a Planning Agent Worth Running
A planning agent is worth running when the brand publishes more than 8 articles per month, has a defined topic cluster strategy, and can absorb a 4-week rollout. Below that bar, the cost of building and maintaining the agent exceeds the savings from automation. Above that bar, the agent pays back in 90 days or less and compounds from there.
The decision matrix is straightforward. Teams that publish 4 or fewer articles per month should run a copilot, not an agent. The agent's planning logic adds overhead that does not pay off at low volume. Teams that publish 8 to 20 articles per month are the sweet spot — the agent fits the work, and the team has enough volume to surface the agent's failure modes early.
Teams that publish more than 20 articles per month need an agent. At that volume, human planners cannot hold the inventory in their heads, cannibalization becomes routine, and the cost of a missed scoring decision compounds across dozens of articles. The agent is the only way to keep the system from drifting.
See the planning loop in action. Stacc runs 30+ fact-checked articles per month using a planning agent that scores 600 keyword candidates per week. The same engine that ships our content can ship yours. Start a free trial of Stacc →
Common Mistakes to Avoid with AI Content Planning Agents
The mistakes below come from the 11 implementations Stacc has run and the failures we have audited at other companies. Each one is preventable with a small change to the rollout plan.
- ✓ Skipping the content inventory and letting the agent cannibalize existing rankings
- ✓ Running without a topic cluster whitelist and watching the agent drift into irrelevant territory
- ✓ Using a single keyword data source and getting wrong volume and difficulty scores
- ✓ Generating briefs from free-form prompts instead of templates
- ✓ Ignoring conversion data and letting the agent chase traffic that does not convert
- ✓ Switching to 100% agent-generated briefs in one week instead of staging the rollout
- ✓ Removing the senior strategist after the agent goes live and losing the brand voice owner
- ✓ Skipping the SERP format check and producing briefs that do not match the dominant content type
- ✓ Letting the agent generate briefs without internal link verification, which breaks site architecture
- ✓ Running the agent without a kill switch for off-brand topic proposals
The kill switch matters more than most teams expect. A planning agent that proposes 20 topics a day produces 600 topics a month, and even a small drift rate means dozens of bad proposals reach the queue. The kill switch lets a human flag a topic as off-brand with one click, and the agent learns from the flag the next time it scores a similar candidate.
What practitioners are saying on X
Content operations advice ages quickly. Here is high-signal operator discussion on X about quality, refresh, and systems.
- @jakezward (Feb 2026): 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers as a KPI, proprietary data as a moat, and content refresh beating net-new AI slop. See the post on X.
- @varunram (Jul 2026): Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research still separate winners from farms. See the post on X.
- @HlynurStefDev (Jul 2026): Public case: niche site traffic jumped from ~18 to 4,162 Google visits/month after focused technical/on-page SEO work (GSC screenshots claimed) — reminds that fundamentals still move numbers. See the post on X.
Grok, AI Overviews, and multi-engine visibility
AI/search topics like “ai agents content planning” need multi-engine notes: AI Overviews, ChatGPT/Perplexity, and Grok. Lead with extractable answers; keep claims consistent with public expert discussion.
- Google AI Overviews: Use passage-ready answers, tables, and FAQ schema where relevant.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Frequently Asked Questions
A planning agent decides what to write and produces a brief. A generation tool writes the article from the brief. The two are different layers of the stack. Most teams need both, but they fail in different ways and require different oversight. A planning agent that picks bad topics will waste writer time even if the generation tool is perfect.
The agent itself runs on language model APIs at about $4 to $12 per brief in 2026. Add data subscription costs for DataForSEO or Ahrefs at $99 to $499 per month. Total operating cost for a small team is around $300 to $600 per month, which produces 30 to 60 briefs. The payback comes from replacing $80 to $250 per brief in human strategist time.
Yes, with adjustments. Local businesses need an agent that weights local intent heavily and reads from Google Business Profile data alongside keyword tools. The whitelist should include service areas and neighborhood names. Most off-the-shelf planning agents miss this, so local businesses often need a custom config or a vertical-specific tool.
The agent shows operational ROI in 30 days through brief generation time savings. Ranking ROI takes 90 to 180 days because new articles need that long to mature in search. Teams that expect ranking lift in 30 days are setting themselves up for false negatives and premature shutdowns.
No. It replaces the brief generation work a junior strategist does. The senior strategist still owns the topic cluster whitelist, the brand voice document, the conversion attribution model, and the kill switch. A planning agent without a senior owner drifts within 60 to 90 days in every case we have observed.
Real-time keyword data from DataForSEO, Ahrefs, or Semrush. First-party analytics from GA4 and Search Console. CRM data for conversion attribution. Competitor SERP snapshots from the same keyword API. Internal content inventory from the CMS. Brand voice document from a versioned document store. Five inputs minimum.
The agent should not publish anything. It generates briefs that humans or writing agents act on. The thin content risk is handled at the generation and review stage, not the planning stage. The duplicate content risk is handled by the inventory check the agent runs before scoring any candidate keyword.
Conclusion
AI content planning agents are now the default infrastructure for teams publishing more than 8 articles a month. The four-stage loop — intake, scoring, brief generation, scheduling — is well understood, the failure modes are documented, and the rollout pattern protects existing rankings when teams stage the deployment correctly.
The team that wins with planning agents treats them as systems, not tools. The agent has a job description, a kill switch, a senior owner, and a monthly audit. The brand voice document is versioned. The whitelist evolves. The metrics get reviewed.
Here is what to take away:
- Planning agents decide what to write, not what to say
- A weighted scoring formula across six variables produces better topic queues than a flat keyword list
- Template-driven brief generation beats free-form prompting by 3× on editorial throughput
- A 4-week staged rollout protects 94% of existing rankings versus 62% for one-week switches
- The senior strategist stays — the agent replaces the junior strategist work
The brands that ship 30 articles a month at the quality bar they ship 5 articles a month today are the ones running planning agents with the right guardrails.
Ship 5× more content without losing brand voice. Stacc's planning agent runs the full loop — topic discovery, scoring, brief generation, and scheduling — on the editorial calendar you already use. We test on 70+ industries before shipping production briefs. Start a free trial of Stacc →
Related Tools & Resources
Free SEO Tools:
Best Lists:
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @jakezward on X — 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers
- [3] @alexgroberman on X — Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category
- [4] @varunram on X — Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research
- [5] Referenced source — www.ibm.com

Researched, written, and published articles that compound organic traffic.