How LLM citations work: the 4-stage pipeline from crawling to citation, ranking signals AI models use, platform differences, and how to get your content cited.
Most pages that rank #1 on Google never get cited by ChatGPT, Perplexity, or Claude. That is the problem buyers are ignoring.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
A 2026 Writesonic study of GPT-5 behavior found only 7% citation overlap between the base model and the thinking model on the same prompts. Ahrefs analyzed 17 million citations and found 65% go to pages published in the last year. And Omniscient Digital mapped 23,387 citations across ChatGPT and Perplexity. Revealing that Google rank barely predicts who gets picked.
So the question is no longer whether you rank. It is whether the model can retrieve, extract, and trust your page.
This guide explains how LLM citations work, stage by stage. You will learn the 4-stage pipeline every major model uses, why different platforms cite different sources, and the exact failure points that keep most pages invisible.
We publish 3,500+ blogs a month across 70+ industries. We watch which pages get pulled into AI answers and which never surface. The patterns repeat. Here is what you will learn in this guide:
- The 4-stage pipeline every LLM runs when it builds a citation
- Why query fan-out produces different answers for similar prompts
- How ChatGPT, Perplexity, Claude, and Gemini differ in citation behavior
- The ranking signals that matter (and the ones that do not)
- Why the extraction stage is the silent killer of citation rates
- How to read and measure hallucinated citations
- How to track LLM citations across every model
- The content structures that actually get cited in 2026

Table of Contents
- Chapter 1: What LLM Citations Actually Are
- Chapter 2: The 4-Stage LLM Citation Pipeline
- Chapter 3: How Each Major LLM Handles Citations
- Chapter 4: Query Fan-Out and Why It Reshapes Citations
- Chapter 5: The Ranking Signals LLMs Use to Pick Sources
- Chapter 6: Why Extraction Is Where Most Pages Fail
- Chapter 7: The Hallucinated Citation Problem
- Chapter 8: How to Track LLM Citations for Your Brand
- Chapter 9: How to Write Content That Gets Cited
- FAQ
Chapter 1: What LLM Citations Actually Are
An LLM citation is a link or reference that an AI model attaches to a generated answer. It points the reader back to a specific source the model used to construct its reply.
This is not the same thing as an old-school backlink. A backlink is a link from one public web page to another. A citation is a runtime attribution produced by a language model when it answers a user question.
The difference between a citation and a mention
A citation includes a clickable or named source: "According to Ahrefs, 17M AI citations show..." or a numbered reference the model lists at the end of its answer. The reader can verify the claim.
A mention is different. ChatGPT might say "Stacc publishes 30 articles a month" inside a fluent paragraph with no link. That is an unlinked mention. It still builds brand awareness and entity associations. But it is not a citation.
The shift matters because LLM citations drive real referral traffic. Semrush tracked cited domains and found a 92% higher CTR compared to standard organic results on the same queries.
Why LLMs cite sources at all
Models have two ways to answer any question. They can draw from their internal parametric knowledge baked into training. Or they can retrieve fresh documents from the web in real time.
When a model retrieves, it needs to attribute. Without attribution, users cannot trust the output on time-sensitive or niche topics. Every major AI product. ChatGPT, Perplexity, Claude, Gemini, AI Overviews. Now runs a retrieval layer with citation rendering.
The rule is simple. No retrieval, no citation. The model can still write confidently from training data. But it cannot point to a verifiable source the user can check.
For a deeper definition, see our explainer on what generative engine optimization means and the distinction between GEO vs SEO.
Chapter 2: The 4-Stage LLM Citation Pipeline
Every modern LLM citation moves through the same 4 stages. Miss any stage and the page does not get cited. This is the mental model to hold.
Stage 1: Retrieval
The model takes the user prompt and passes it to a search index. For ChatGPT that means Bing and a proprietary crawler. For Perplexity it is a live web search and their own index. For Gemini it is Google search. For Claude it is Brave and other retrieval partners.
The retrieval layer returns a candidate pool of 20 to 100 pages. These are the pool the model will read from. If your page is not in the candidate pool, nothing else matters.
Stage 2: Ranking
The model now ranks the candidate pool. It weighs organic authority, brand recognition, freshness, topic relevance, and structural clarity. The top 5 to 15 pages move to the next stage.
A 2026 upGrowth study found brand authority had the strongest correlation with citation selection at 0.334. Multi-platform presence across 4 or more channels came second. Freshness in the last 12 months came third.
Stage 3: Extraction
This is where most pages die. The model now reads the top-ranked pages and tries to pull clean, self-contained facts that answer the user's exact question.
A page can be authoritative and fresh and still fail here. If the answer is buried in a 500-word paragraph with no clear topic sentence, the model cannot extract a clean fact. It moves on to the next page.
Stage 4: Attribution
Finally, the model maps extracted facts to their source URLs. It decides how to render the citation. As a numbered footnote, inline link, or end-of-answer list. The user sees the final citation.
| Stage | What Happens | Main Failure Mode |
|---|---|---|
| Retrieval | Model pulls 20-100 candidate pages from search index | Page not indexed, blocked by robots.txt, or low query relevance |
| Ranking | Candidates scored on authority, freshness, structure | Thin domain authority, stale content, no brand signals |
| Extraction | Model reads top pages and pulls clean facts | Answers buried, no clear topic sentences, missing structure |
| Attribution | Model maps facts to URLs and renders citation | Model misattributes to different source, hallucinates URL |
The pipeline is sequential. A page passes or fails at each stage. Your job is to pass all 4.
Want 30 articles a month engineered for LLM citation without lifting a finger? Stacc handles research, writing, schema, and publishing on autopilot.
Chapter 3: How Each Major LLM Handles Citations
Not every model runs the pipeline the same way. Citation behavior differs by platform. You need to understand the divergence to plan coverage.
ChatGPT
ChatGPT uses a mix of cached indexes and real-time Bing browsing. It cites 2 to 4 sources per answer on average. Zapier's 100-query test found ChatGPT's citations were verifiable 76% of the time.
Wikipedia dominates ChatGPT's source mix. It accounts for 47.9% of citations among the top 10 most-cited sources. Reddit, LinkedIn, YouTube, and major news outlets fill the rest. See our full breakdown of how Wikipedia dominates ChatGPT citations.
GPT-5 thinking models behave differently from the base model. The Writesonic study found GPT-5.4 Thinking fan-outs to 8.5 queries per prompt on average. The base GPT-5.3 fires 1 query. That produces radically different citation pools.
Perplexity
Perplexity runs live web search and cites 4 to 8 sources per answer. Citation density is the highest of any major model. Zapier's test rated Perplexity's citation accuracy at 89%.
Perplexity indexes Reddit, Wikipedia, YouTube, and commercial blogs aggressively. In a 501-site benchmark, Perplexity accounted for 47% of all tracked AI citations across major engines. For optimization tactics, see our guide on Perplexity SEO and how to optimize for Perplexity.
Gemini and Google AI Overviews
Gemini synthesizes a few top sources and lists them at the end. AI Overviews cite 3 to 8 links in the generated box. A Semrush study of AI Overviews found 76% of cited URLs rank in Google's top 10 organically.
Gemini rewards Google rank more than other models. If you already rank well, you have a real shot at AI Overview citation. See our guide on how to rank in AI Overviews and AI Overview optimization.
Claude
Claude uses retrieval partners including Brave and real-time web access. Citation volume is lower than Perplexity but higher than base ChatGPT. Claude tends to cite 3 to 6 sources per answer and prefers pages with clear heading structure and citations of its own.
| Model | Sources per Answer | Citation Accuracy | Dominant Source Type |
|---|---|---|---|
| ChatGPT | 2-4 | 76% | Wikipedia, Reddit, news |
| Perplexity | 4-8 | 89% | Reddit, commercial blogs, Wikipedia |
| Gemini / AI Overviews | 3-8 | 84% | Top 10 Google results |
| Claude | 3-6 | 81% | Structured guides, research |
The takeaway is blunt. You cannot optimize for "AI citations" as a single thing. You optimize per model. Read our LLM visibility guide for the coverage plan.
Chapter 4: Query Fan-Out and Why It Reshapes Citations
Query fan-out is the single most important concept in LLM citations. It explains why two similar prompts produce completely different source lists.
What fan-out actually does
When a user types a prompt, the model does not run one search. It expands the prompt into 3 to 15 sub-queries and runs each independently. Each sub-query returns its own candidate pool.
For the prompt "best CRM for small service businesses," a thinking model might fire:
- best CRM small business 2026
- CRM comparison service business
- affordable CRM under $50 per user
- HubSpot vs Salesforce for small teams
- Zoho CRM small business review
- CRM with GBP integration
- top-rated CRM on G2 2026
Each sub-query pulls 20 to 50 pages. The model then merges, deduplicates, and re-ranks across all pools. Your page might rank #3 for one sub-query and never appear in another.
Why fan-out breaks traditional SEO thinking
Traditional SEO targets one head term per page. Fan-out rewards the opposite pattern. The page that wins citations is the one present across 4 to 8 sub-queries in the cluster.
Semrush research found only 27% of fan-out keywords stay consistent across two runs of the same prompt. That means coverage matters more than any single keyword rank.
The practical implication
To get cited, you need topical depth, not just one ranking page. Publish 10 posts across the question cluster instead of 1 page chasing 1 term. That is the entire logic behind topical authority as a citation lever.
Our content cluster framework walks through how to map fan-out coverage into a publishing plan.
Chapter 5: The Ranking Signals LLMs Use to Pick Sources
Once the retrieval layer pulls the candidate pool, the model ranks those pages. The ranking signals are not the same as Google's core algorithm. Different weights, different priorities.
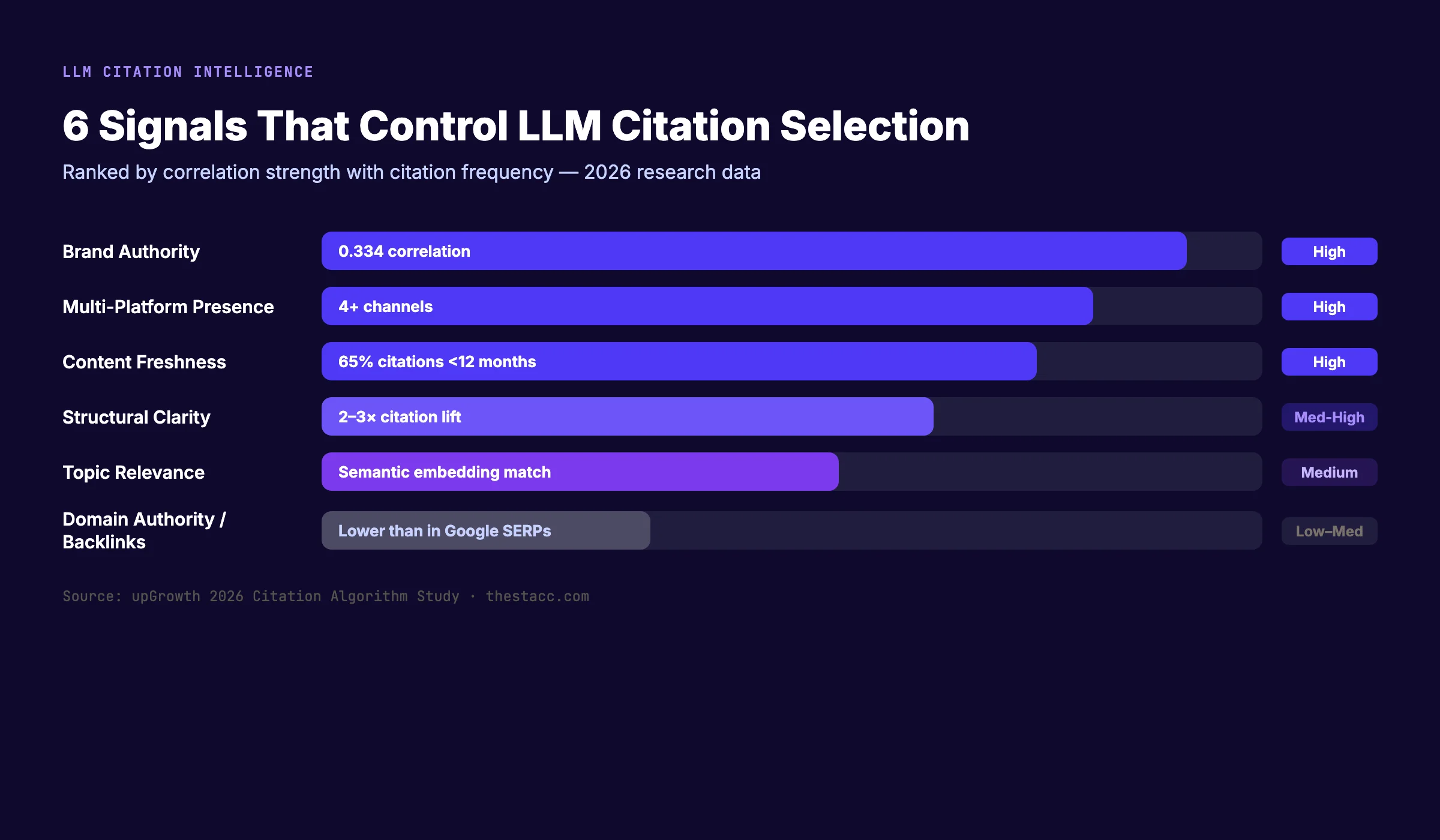
Brand authority
Brand authority is the strongest single predictor of LLM citation. The upGrowth 2026 study pegged the correlation at 0.334. Higher than domain authority, higher than freshness, higher than backlink count.
Brand authority is measured by unlinked mentions across trusted surfaces. Reddit threads. YouTube videos. News articles. Wikipedia. Podcast transcripts. The model infers authority from how often your brand co-occurs with topic-relevant entities. Our brand entity optimization guide walks through the full entity graph.
Multi-platform presence
The second strongest signal is presence across 4 or more platforms. If you live only on your own domain, the model has one data point. If you show up on Reddit, YouTube, LinkedIn, and niche forums, the model has 4 independent signals saying you are real.
Freshness
Ahrefs found 65% of AI bot traffic targets content published in the last 12 months. 79% of citations go to content updated in the last 24 months. Only 6% of citations go to content older than 6 years.
Models prefer recent content because user prompts are usually time-sensitive. "Best CRM 2026" cannot be answered from a 2019 article. Updates reset the freshness clock, which is why we refresh cited pages on a 90-day cadence.
Structural clarity
Pages with direct answers, clean H2s, tables, bullet lists, and FAQs get cited 2 to 3 times more often than unstructured prose. The reason is extraction. Structure lets the model pull a clean passage in one pass.
Topic relevance and semantic match
The model embeds the user query and every candidate page into the same vector space. Pages that sit close to the query in that space score higher. This is why a short, on-topic page can beat a long, loosely-related one.
Schema and structured data
Schema is not as decisive as brand authority, but it still helps. FAQPage schema, HowTo schema, and Article schema all correlate with higher extraction rates. See our guides on schema for AI search and schema markup for blog posts.
Ranking signal weights
| Signal | Approximate Weight | Why It Matters |
|---|---|---|
| Brand authority | High (0.334 correlation) | Signals the model can trust the source |
| Multi-platform presence | High | Confirms the brand exists beyond its own domain |
| Freshness (last 12 months) | High | Matches time-sensitive user prompts |
| Structural clarity | Medium-High | Enables clean extraction |
| Topic relevance (embedding match) | Medium | Filters to on-topic candidates |
| Schema / structured data | Medium | Boosts extraction confidence |
| Domain authority / backlinks | Low-Medium | Matters less than Google SERPs |
Your brand needs to show up across Reddit, YouTube, and 70+ industries to get cited. Stacc publishes 30 articles a month that build exactly that footprint.
Chapter 6: Why Extraction Is Where Most Pages Fail
Retrieval and ranking get most of the attention. Extraction is where real citations are lost. A page can be authoritative, fresh, and well-ranked and still fail at extraction.

What extraction actually does
After ranking, the model reads each top page and chunks it into passages. Each passage is tested: can I pull a clean, self-contained answer to the user's question from this chunk?
If the chunk has a clear topic sentence and a direct answer, it wins. If the chunk is a setup paragraph with the real answer 200 words later, it loses. The model moves to the next page.
The 3 most common extraction failures
Failure 1: Buried answers. The page does answer the question. In paragraph 7. The model only pulled the top 3 chunks. Your answer never got read.
Failure 2: No self-contained passages. The page explains the concept across 5 paragraphs, each referring back to the last. No single chunk stands alone. The model cannot extract a clean fact.
Failure 3: Hedged language. "It depends," "generally," "in most cases" all reduce extraction confidence. The model wants a direct assertion it can attribute without caveats.
What extraction-ready content looks like
A strong answer chunk follows a simple structure. The H2 or H3 asks the question. The first sentence under it gives the direct answer. The next 2 to 3 sentences support the answer with specifics.
That pattern works because it mirrors how the model processes chunks. See our AI Citation Readiness Checklist for the full structural audit and our AI citability score framework.
The first-200-words rule
Kevin Indig's analysis of 1.2 million ChatGPT answers found 44.2% of citations come from the first 30% of content. The model front-loads its reading. Front-load your answers. Put the direct answer within the first 200 words of every section. Our first 200 words playbook walks through the exact pattern.
Entity density
Entity density is the number of named entities per 100 words. Heavily cited content averages 20.6% entity density. Low-cited content averages 8 to 12%. Name the tools, products, companies, studies, and experts explicitly. Do not rely on pronouns.
Chapter 7: The Hallucinated Citation Problem
Citation systems fail in a unique way. The model invents a citation. The link does not exist, or it points to a real page that does not say what the model claims.
How often it happens
A 2025 study published in JAMA found GPT-4 hallucinated 28% of its academic citations outright. CiteVerifier tracked 2.2 million real-world citations and found 1.07% were fabricated URLs. And fabrication rates increased 80.9% year over year.
The worst case is not fabrication. It is misattribution. The link is real, the page exists, but the claim is not actually on the page. The model pattern-matched from training data and then glued on the closest-looking source.
Why hallucination happens
Models generate fluent text first and map citations second. That sequence is the root cause. If the model writes a plausible-sounding claim, it will find the most topically similar URL in its retrieval pool. Even if that URL does not support the specific claim.
What it means for your brand
Two practical consequences. First, if you are cited, always verify the claim actually matches your page. If the model misattributes, correct the public record on Reddit, LinkedIn, or X. The correction often gets indexed.
Second, hallucination creates an opportunity. If a model is regularly inventing a stat on a topic you cover, publish the real number with a clear source. The next retrieval round often surfaces the correct source and replaces the hallucinated one.
How to audit your cited pages
Run your brand name through ChatGPT, Perplexity, Claude, and Gemini weekly. Check every claim. If a citation attributes a claim you never made, file feedback and update the source page to own the claim explicitly. See our guide on how to track AI search visibility.
Chapter 8: How to Track LLM Citations for Your Brand
You cannot improve what you do not measure. LLM citation tracking is new, fragmented, and noisy. But you can build a working system.
The 3 layers of LLM tracking
Layer 1: Manual prompt audits. Pick 20 prompts your customers actually ask. Run them through ChatGPT, Perplexity, Claude, and Gemini weekly. Log which sources get cited. This is the fastest way to see baseline citation share.
Layer 2: Referral traffic analysis. Filter Google Analytics by referrer for chatgpt.com, perplexity.ai, gemini.google.com, and claude.ai. The session volume and landing pages tell you which pages are actually getting clicks from AI citations.
Layer 3: Dedicated LLM tracking tools. Tools like Profound, Otterly, HubSpot AI Search Grader, and Peec AI sample hundreds or thousands of prompts per day and report citation share over time. Most cost $99 to $499 a month.
What metrics matter
| Metric | What It Tells You |
|---|---|
| Citation share | % of tracked prompts where your brand appears |
| Share of voice | How often you appear vs named competitors |
| Citation position | Is your link first, second, or buried? |
| Citation accuracy | Is the claim actually on your page? |
| Referral traffic | Real clicks from LLM answers |
| Mention-to-citation ratio | How often unlinked mentions become linked citations |
How often to audit
Weekly is the minimum for active brands. Monthly works for stable niches. Our customers tend to audit 20 prompts per week across 4 models, then roll up monthly trend reports. See our LLM visibility guide for the full tracking workflow.
Build a prompt map first
Before you buy a tool, write the prompt map. List the 20 to 50 questions your target customer asks before they buy. Group them by intent. Track citation share on each group separately. A tool without a prompt map produces meaningless averages.
Chapter 9: How to Write Content That Gets Cited
All 8 chapters so far describe the mechanism. This chapter converts the mechanism into a writing checklist. Every post you publish should pass these tests.
The 9-point citation checklist
- ✓ Direct answer in the first 100 words. The model front-loads its reading. Front-load your answers.
- ✓ H2 and H3 questions that mirror real prompts. "How does X work" beats "Understanding X" every time.
- ✓ Self-contained passages under each heading. Every chunk must make sense without the paragraph above it.
- ✓ Named entities over pronouns. Write "Perplexity" not "it," "Stacc" not "the service."
- ✓ Tables and bullet lists for comparisons. Structure amplifies extraction confidence.
- ✓ A stat with a source in the first 200 words. Cited sources love to cite other cited sources.
- ✓ Publication date visible. Freshness is a weighted signal. Show it.
- ✓ FAQPage or Article schema. Boosts extraction confidence. Easy to implement.
- ✓ Internal links to related answers. Builds the topical cluster that fan-out rewards.
The answer-first paragraph pattern
This pattern works across every model. Write every section like this:
- Sentence 1: The direct answer to the section's question. One claim. No hedging.
- Sentences 2-3: The evidence, example, or stat that supports the claim.
- Sentences 4-5: The implication or next step.
That is it. Every H2. Every H3. No setup paragraphs.
How Stacc applies the citation framework
Every Stacc article runs through this framework at publish time. Research pulls the fan-out questions from SERP data. Writing follows the answer-first pattern. Schema and internal links get added automatically. Images include descriptive alt text for multimodal extraction.
Our The Content Compound Effect works because we treat every post as one tile in a topical cluster. Ten posts covering the fan-out of a high-value query win far more citations than one flagship post.
Want to skip the work? We publish 30 LLM-ready articles a month for $99. Every article hits every point on the checklist above. See what we publish and how it stacks.
30 articles. Every one engineered for LLM citation. $99 a month.
What practitioners are saying on X
Local still bottoms out at GBP completeness, category, reviews, and NAP.
- @noelcetaSEO (Sep 2025): Local SEO playbook still centers complete GBP, NAP consistency, quality citations, local keywords, location content, review velocity, and local links. See the post on X.
- @irentdumpsters (Jan 2026): Most businesses have a GBP; few fully optimize every ranking-relevant section for Map Pack visibility. See the post on X.
- @EldarCohenSEO (Jul 2026): 2026 WhiteSpark-oriented reminder: primary Google Business category is a top Map Pack ranking factor — wrong primary category can erase visibility for money queries. See the post on X.
Grok, AI Overviews, and multi-engine visibility
For topics covered in “how llm citations work”, multi-engine visibility still starts with clear definitions, sourced statistics, and extractable section answers. Grok additionally factors live X discussion — keep public claims consistent with this page.
- Google AI Overviews: Use passage-ready answers and structured data.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Publish content built for Google and AI citations. theStacc’s Content SEO module ships SEO-scored articles structured for rankings and generative engines — including clearer entity pages models like Grok can quote.
How to measure multi-engine visibility in 2026
Split KPIs across classic search, AI Overview citations, chat referrals, and Grok-ready brand accuracy.
- GSC: non-brand clicks and query annotations.
- Citations: named in AI answers?
- Referrals: ChatGPT / Perplexity in GA4.
- Grok: on-site claims match public X discussion.
FAQ
LLMs run a 4-stage pipeline: retrieval, ranking, extraction, attribution. The model pulls 20 to 100 candidate pages from a search index, ranks them on brand authority and freshness, extracts clean facts from the top 5 to 15 pages, and maps the facts to source URLs. Brand authority has the strongest correlation with citation selection at 0.334.
No. Gemini rewards Google rank more than any other model, but even there only 76% of AI Overview citations come from the top 10. ChatGPT, Perplexity, and Claude often cite pages that rank outside the top 10. A Surfer study found 67.82% of AI Overview cited sources do not rank in Google's top 10 for the same query.
A backlink is a static link from one public web page to another. An LLM citation is a runtime attribution produced by an AI model when it answers a user question. Backlinks drive rank signals. Citations drive referral traffic and brand authority signals the next retrieval round reads.
CiteVerifier tracked 2.2 million real-world citations and found 1.07% of URLs were fabricated outright. Misattribution. Where the link is real but the claim is not on the page. Happens in 30% to 50% of individual statements across major models. Always verify every claim attributed to your brand.
Perplexity cites 4 to 8 sources per answer and ranked highest on citation accuracy at 89% in Zapier's 100-query test. ChatGPT cites 2 to 4 sources. Gemini AI Overviews cite 3 to 8. Claude cites 3 to 6. Perplexity also accounted for 47% of all tracked citations in a 501-site benchmark.
Structured content with direct answers, H2 questions, tables, bullet lists, and FAQs gets cited 2 to 3 times more often than unstructured prose. Freshness matters too: 65% of AI citations go to content published in the last 12 months. Entity density of 20% or higher correlates with heavy citation.
That is how LLM citations work end to end. The mechanism is not a black box. It is a 4-stage pipeline you can engineer against, chapter by chapter. The brands that ship 30 citation-ready articles a month win the next 3 years of search. The brands still writing 1 flagship post a quarter will not.
Start small. Pick one topic cluster. Write 10 posts that pass the 9-point checklist in Chapter 9. Run weekly audits across ChatGPT, Perplexity, and Gemini. The citation share will move.
. Try Stacc free for 3 days.
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @jakezward on X — 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers
- [3] @alexgroberman on X — Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category
- [4] Referenced source — writesonic.com

Researched, written, and published articles that compound organic traffic.
Weekly local SEO teardowns
One practical email a week. Map Pack, GBP, AI Overviews — no fluff. Unsubscribe anytime.