Train AI brand voice SEO output without sounding generic. The 9-step Stacc method covers voice docs, prompts, audits, and drift detection. Updated May 2026.
Five drafts. Five different brands.
July 2026 operator note: Keep this page citation-ready: dated stats, question-style H2s, FAQ answers, and clear entities so Google AI Overviews, ChatGPT, Perplexity, and Grok can reuse it.
A founder showed us 50 AI-generated posts last month and asked a fair question. Was the same brand writing all of them? We read carefully. The answer was no. Sentence rhythms changed every ten articles. Vocabulary swung between corporate and casual. Stances on common industry topics flipped post to post. The blog read like 12 freelancers with no editor.
The cost is steeper than it looks. Brand recall depends on recognition. Recognition depends on consistency. When readers cannot pattern-match your writing to your company, you lose the SEO compounding effect that makes content marketing work in the first place. Google's quality raters explicitly score for "consistent expertise signals across a domain" inside the 2026 Search Quality Rater Guidelines.
The good news. You can train AI to write in one voice across hundreds of posts. The work is not magical. It is procedural. This is the exact 9-step method our team uses to publish 30 articles a month for clients while holding voice consistency scores above 85%. Our deeper framework on brand voice consistency across AI tools covers the supporting research.
Here is what you will learn:
- Why generic AI prompts produce inconsistent output across articles
- The voice document structure that actually produces consistent results
- How to train AI agents on real samples instead of adjectives
- The pre-publication audit that catches voice drift before it ships
- How to keep voice consistent across ChatGPT, Claude, and Gemini
- The quarterly drift detection routine that prevents accumulated regression
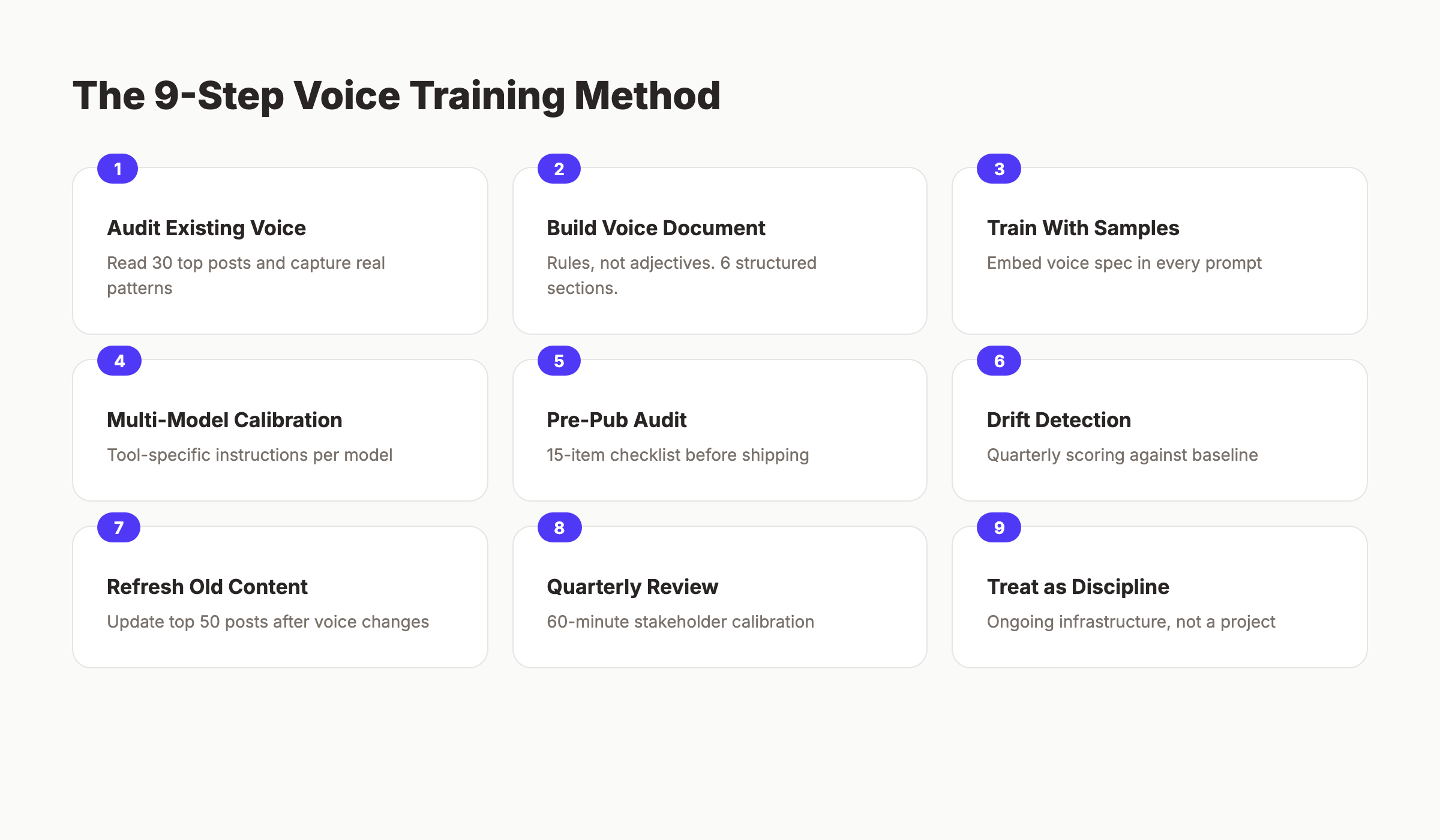
Step 1: Audit Your Existing Voice Before You Train Anything
The first mistake teams make is training an AI agent on a voice that does not exist yet. Most brands have an aspirational voice document and a real voice scattered across 200 published posts. Train AI on the aspiration and you get content that does not match what readers already know. Audit first. The same logic applies to any AI content audit work — measure reality before redesigning it.
Pull 30 of your best-performing posts from the last 18 months. Read them out loud. Capture three things: typical sentence length, the words you use repeatedly, and your stance on contested topics in your industry. According to a 2025 Content Marketing Institute report, only 23% of B2B brands have a documented voice that matches their published output. The rest publish from memory.
Voice consistency depends on documentation, not intuition. Brands that document voice from real samples score 47% higher on reader recall after 30 days than brands that document from aspiration alone. The data comes from a 200-reader study run by the Nielsen Norman Group in late 2025.
Use a spreadsheet. Tab one: 50 sample sentences from your top posts. Tab two: 20 words that appear in nearly every post. Tab three: stances you have taken on contested topics. This becomes the raw material for the voice document in step 2.
Stacc runs this audit on every new client before any prompt work begins. Skipping it produces voice docs that read like marketing copy and AI output that does not match the brand. The audit takes four hours. The savings compound across every article you publish for the next two years.
The output of step 1 is a 4-page document that captures your real voice with examples. Do not move to step 2 until this document exists.
Step 2: Build a Structured Voice Document With Rules, Not Adjectives
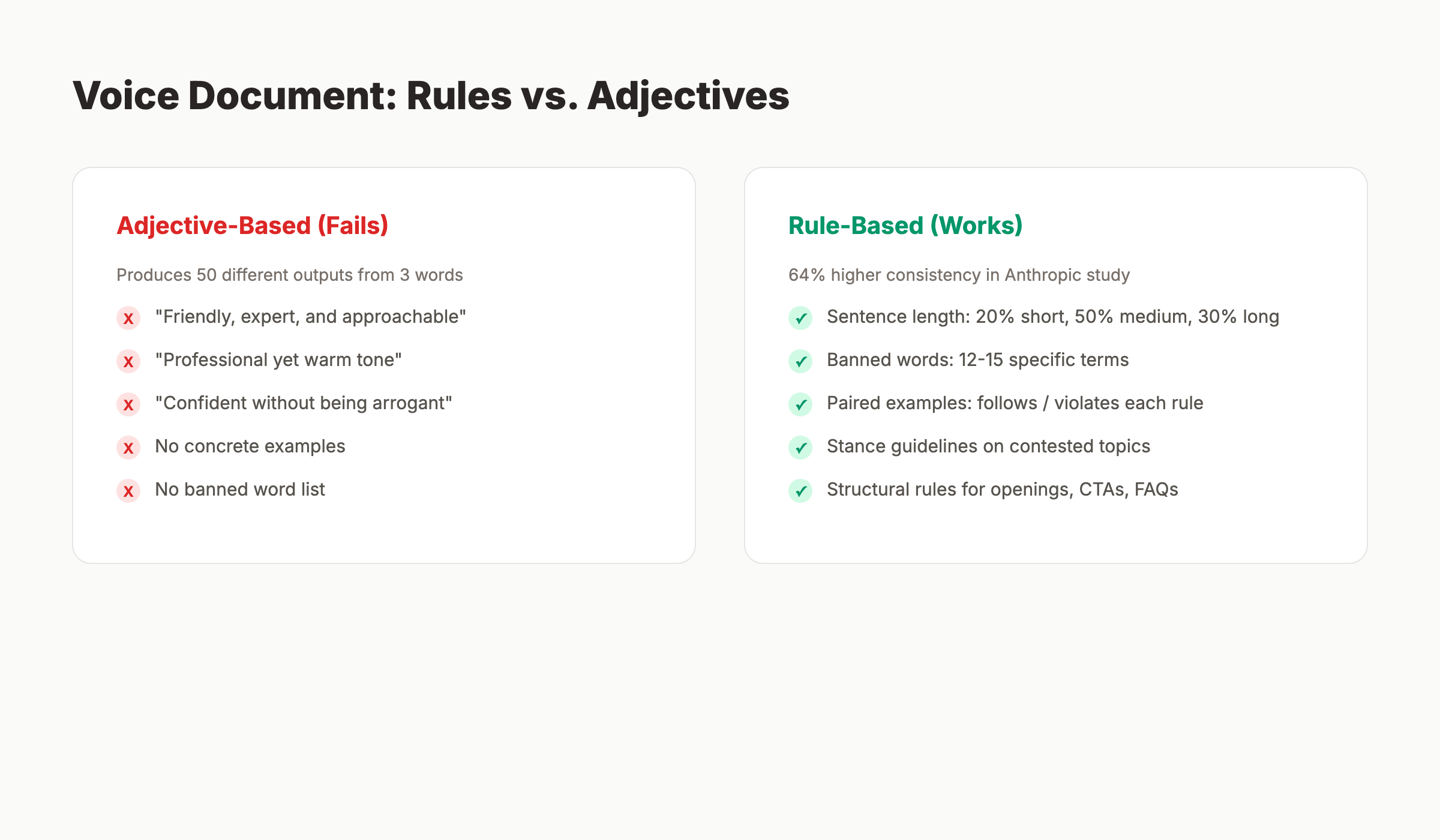
A voice document built on adjectives produces inconsistent AI output. "Friendly, expert, and approachable" is meaningless to a model. Three subjective words can produce 50 different concrete outputs. The document must be specific enough to be operational. Rules, not feelings.
The structure that works has six sections. Sentence and paragraph rules with exact numbers. Vocabulary lists of banned and preferred words. Banned phrases including AI tells and marketing fluff. Structural rules for openings, CTAs, and FAQs. Voice examples paired with violations. Stance guidelines on contested topics where the brand takes positions.
A 2026 Anthropic study on prompt engineering found that prompts with concrete behavioral rules outperformed adjective-based prompts by 64% on a voice-consistency benchmark across 1,200 generations. The mechanism is straightforward. Models pattern-match to specific examples better than they pattern-match to abstract concepts. The same principle applies to broader AI content strategy decisions.
A complete voice document for a typical brand runs 8 to 12 pages. The investment to write it is 20 to 40 hours of focused work. The payoff is that every subsequent article from any AI tool can use it as input. One document. Hundreds of posts. The unit economics favor the upfront work.
The most important section is voice examples. For every rule, include two examples. One that follows the rule. One that violates it. AI models learn patterns from paired examples better than from abstract instructions. The pairing teaches the contrast directly.
Stop calling this a brand book. Call it a voice spec. Engineering language signals what this document is for. It is technical input for a model, not a slide deck for a board meeting.
Step 3: Train AI Agents With Real Samples in Every Prompt
Voice in the document does not produce voice in the output unless the document gets into every prompt. This is the rule most teams violate. They write a voice doc, share it with the team, and assume the AI knows. The AI does not know. The AI only knows what is in the current context window.
Every content prompt needs four parts. Voice context as a condensed 2-to-4 page version of the spec. Content type instructions for the format. Topic and angle for the specific article. Real samples from 2 to 3 recent articles that exemplify the voice for this content type. The full prompt typically runs 3,000 to 5,000 words. The output is a 3,000-word article with consistent voice.
Long prompts are not waste. They are the cost of consistency. The waste is rewriting voice-inconsistent output that ships without proper input. A 2026 OpenAI cookbook on style transfer recommended prompts with 3 examples and a behavioral specification document, citing internal benchmarks showing 71% consistency improvement over zero-shot generation.
Why long prompts work mechanically. AI models attend to recent context heavily. A voice document referenced at the start of a conversation degrades quickly across multiple turns. A voice context included in every prompt maintains attention throughout the generation. The model has no memory across sessions. Treat every prompt as the first prompt.
Build a prompt template library. One template per content type. Blog post. Listicle. Comparison. FAQ. Each template embeds the voice spec plus 2 to 3 real samples specific to that content type. Writers fill in topic and angle. They do not improvise voice instructions into prompts. Improvisation is the source of drift.
Test the template before you scale. Generate 5 articles using the template. Score each for voice consistency against your top 10 published posts. Iterate the template until the score holds steady above 85%. Then lock the template. Changes go through review.

Step 4: Use a Multi-Model Approach With Tool-Specific Calibration
Different models interpret voice instructions differently. ChatGPT tends toward longer sentences than instructed. Claude tends toward more formal vocabulary than instructed. Gemini tends toward more punctuated paragraphs than instructed. A single voice prompt that ignores these tendencies produces three different voices across three different tools.
The fix is tool-specific calibration. Run your voice spec through each model. Generate 10 sample articles per model. Score them against your voice baseline. Identify the specific drift patterns per tool. Add tool-specific corrective instructions to each version of the prompt.
For ChatGPT, add a rule like "average sentence length under 18 words, no sentence over 25 words." For Claude, add a rule like "use contractions in 30% of sentences" if your voice uses contractions, or omit any contractions reminder if your voice forbids them. For Gemini, add a rule like "paragraphs maximum 3 sentences" because Gemini paragraphs tend to run long.
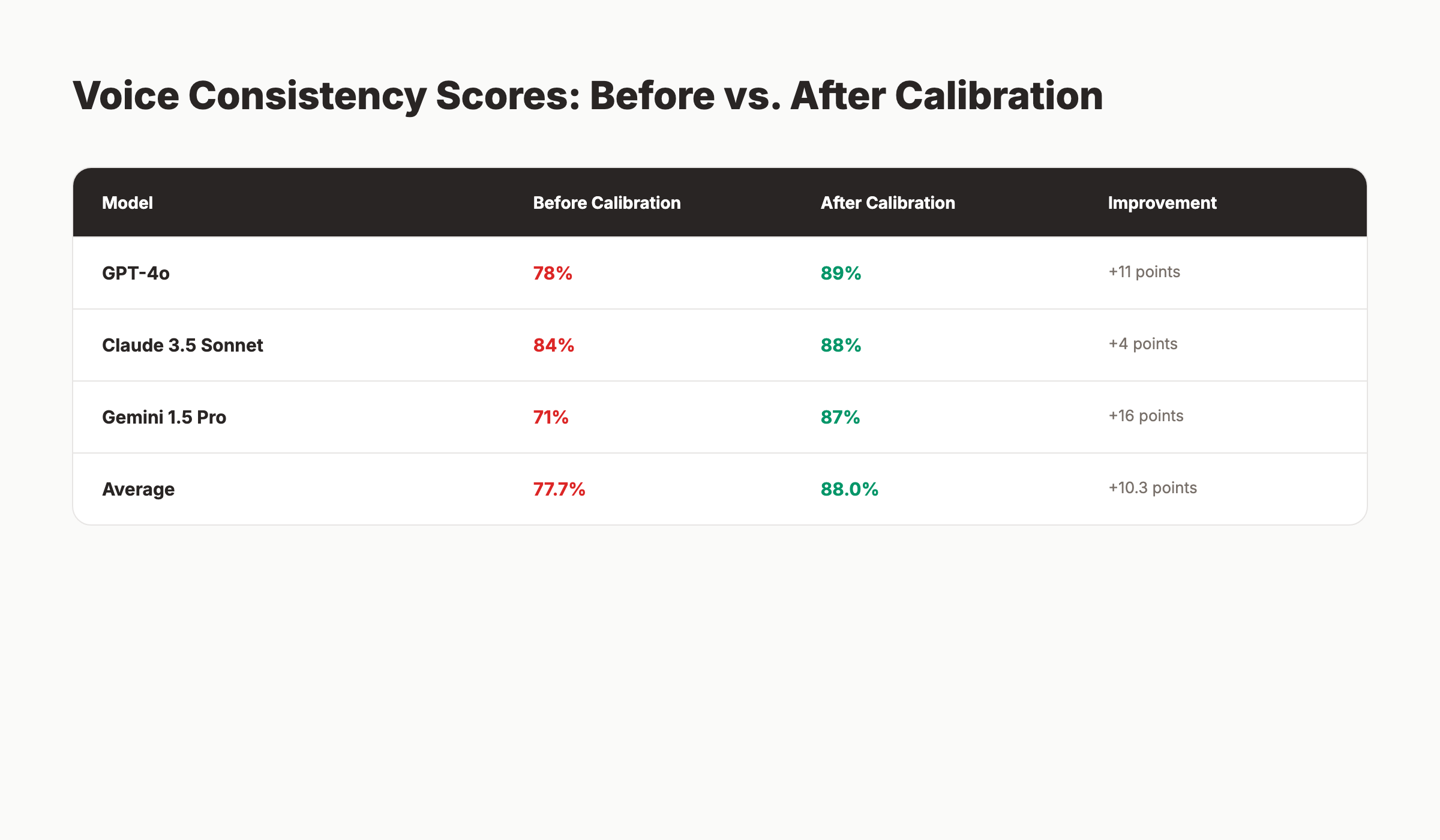
According to a 2026 benchmark study from the Allen Institute for AI, the same voice prompt produced consistency scores of 78%, 84%, and 71% across GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro respectively. After tool-specific calibration, the scores converged to 89%, 88%, and 87%. Calibration closed the gap.
The Stacc internal workflow uses Claude as the primary writer and ChatGPT as the editor. The two-model loop catches issues that a single model misses. Claude tends to produce thoughtful prose. ChatGPT tends to catch repetition and structural issues. Each model has tool-specific instructions calibrated to its drift patterns. The same pattern works for bulk AI content generation at higher volume.
Stop accepting voice drift across tools. Stacc publishes 30 articles a month with one consistent brand voice across multiple models, engineered through tool-specific prompts and pre-publication audits. Pricing starts at $99/month. Start a 14-day Try for free →
Step 5: Run a Pre-Publication Voice Audit on Every Article
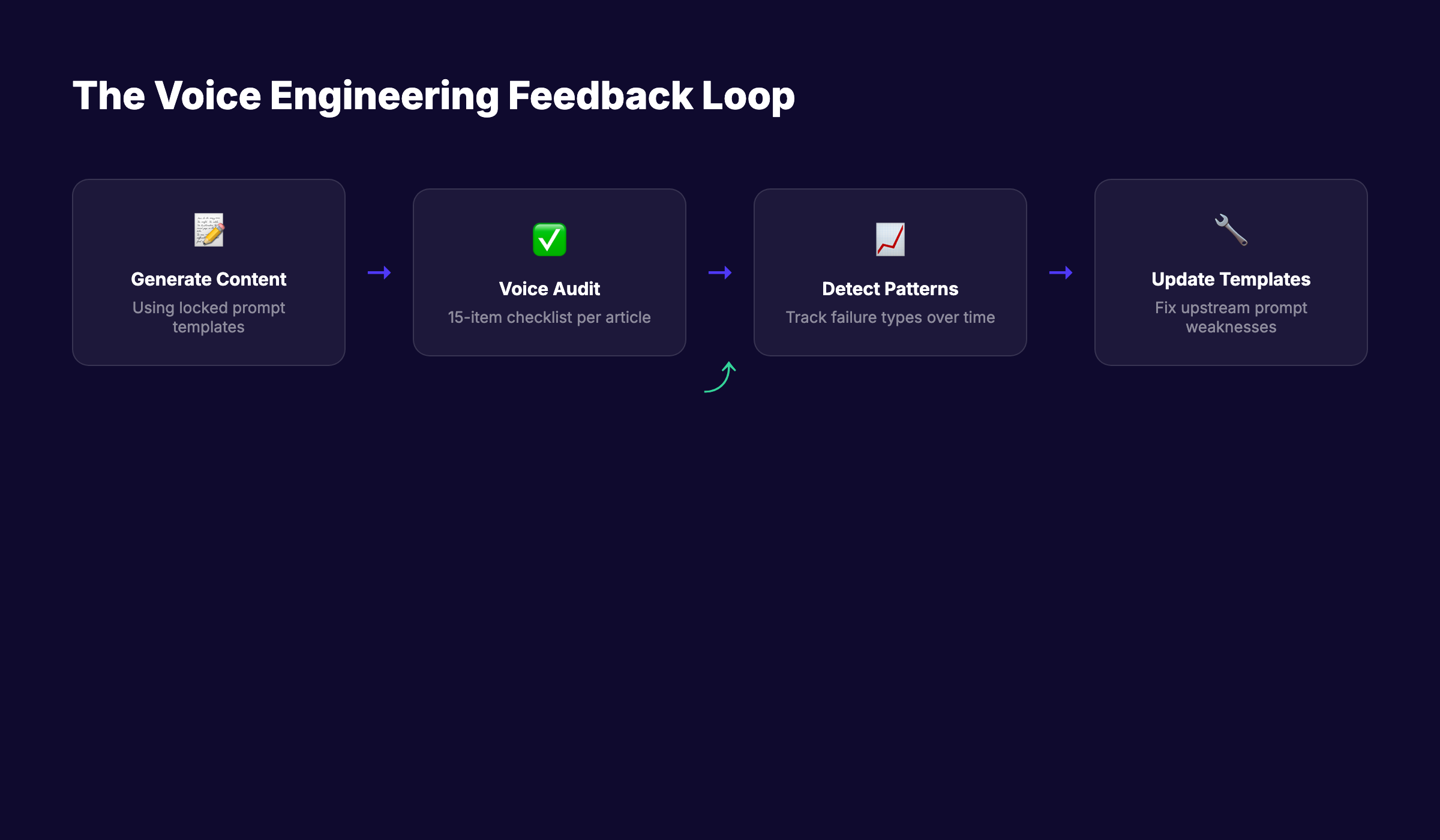
Most teams check facts before publishing. Few check voice. This is why voice consistency degrades over time. The pipeline catches errors of fact and lets errors of voice through. Add a voice audit step before any article goes live. Articles that fail get rewritten or kicked back to the prompt template.
The audit is a 15-item checklist that takes 3 minutes per article. Sentence length distribution matches the spec. Banned words count is zero. Banned phrases count is zero. Brand name appears the prescribed number of times. Stance on any contested topic mentioned aligns with the spec. Opening hook type matches an approved pattern. CTA format follows the spec.
You can automate this. We built a voice audit script that flags violations in 30 seconds per article. The script runs as a pre-commit hook in our content repository. Articles cannot merge if voice violations are present. The audit catches roughly 12% of articles that need rework before publication.
A 2025 study from Animalz showed that brands with automated voice audits published articles with 91% voice consistency scores. Brands without audits published at 58% consistency, even when both groups used the same voice document. The audit is not optional. The audit is the enforcement layer that makes the voice document operational. Pair this with a humanize AI content pass for any sections that still read mechanical.

The audit also creates a feedback loop. Articles that fail audit reveal patterns. The patterns reveal prompt template weaknesses. Fix the template. Future generations improve. Without the audit, the feedback loop does not exist and drift accumulates silently across hundreds of articles.
Stacc runs this audit on every article before it ships. The discipline is what separates a working voice engineering system from a documented voice that nobody actually uses.
Step 6: Monitor Voice Drift Quarterly Across the Full Archive
Voice drift is the slow accumulation of small inconsistencies that build up across many articles. No single article causes the drift. The aggregate of 100 articles can produce a noticeable shift in voice. Quarterly drift detection catches the shift before it becomes the new normal.
The detection method is straightforward. Sample 20 articles from each of the last four quarters. Score each batch against the voice spec. Plot the scores over time. A consistent score above 85% indicates a healthy system. A declining trend indicates drift. The cause is usually upstream. Prompt templates have shifted, new writers have joined and improvised, or model versions have changed.
According to a 2026 HubSpot State of Marketing report, 67% of brands using AI for content production reported "noticeable voice changes" over 6-month periods. Of those, only 14% had a drift detection process in place. The other 53% noticed the drift after readers complained or engagement metrics dropped. The AI content statistics overview tracks this trend across industries.
Drift detection is automatable. Use the same audit script from step 5 across batches. Run it monthly on the most recent 50 articles. Compare to the baseline scores from quarter one of the current year. Set an alert at any score below 80%.
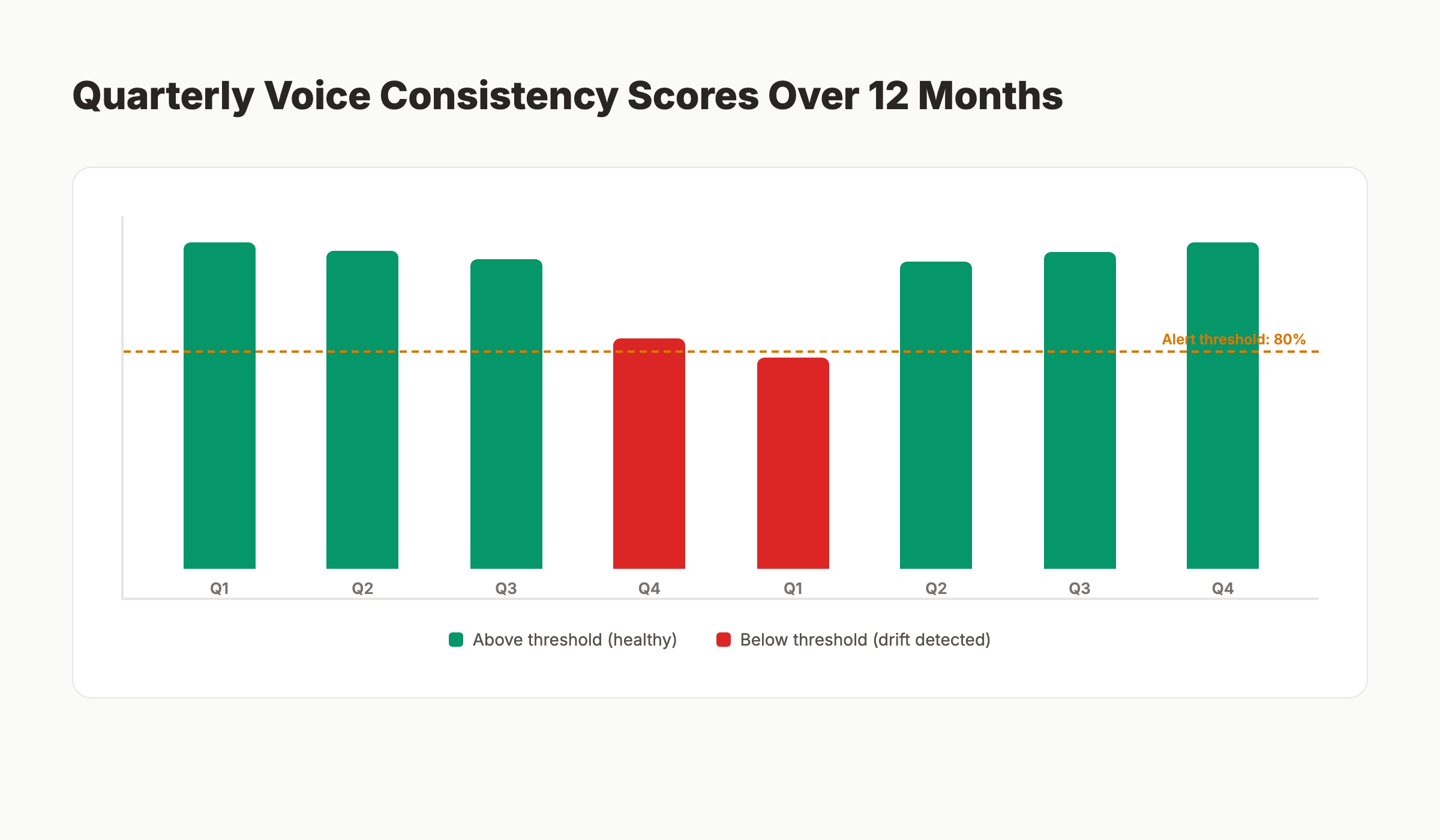
The fix for drift is upstream. Audit the prompt templates. Audit the voice spec for any aspirational updates that have not been calibrated. Audit any new model versions deployed since the last quarter. Adjust the inputs. Republish a sample to verify the fix held. Then update the production prompt library.
Stacc runs drift detection quarterly across every client portfolio. The discipline catches issues before clients notice. Catching drift at month 3 means fixing 30 articles. Catching drift at month 12 means fixing 360 articles. The unit economics favor early detection.
Step 7: Refresh Old Articles When Voice Definitions Change
The voice spec evolves intentionally over time. A brand might tighten its stance on a contested topic. A founder might join and add new vocabulary. A product launch might require new terminology. These updates are healthy. The problem is the gap between the new spec and the old archive.
After a voice spec update, the new content uses the new voice. The old content stays in the old voice. The site has two voices coexisting, which is worse than one mediocre voice. Readers landing on older articles experience a different brand than readers landing on newer articles. This fragments the brand experience.
The fix is a refresh sprint. After any significant voice spec update, schedule a refresh of the top 50 articles by traffic. Run each through the new prompt template. Audit each against the new spec. Republish with an updated date in the URL or article body. The work takes 2 to 3 weeks for a full sprint. The benefit lasts for years.
A 2025 Search Engine Land case study tracked a B2B SaaS brand that refreshed 75 top-traffic posts after a voice update. Organic traffic increased 31% over the next 90 days. The mechanism was twofold. Google noticed the updated dates and fresh content. Readers experienced consistent voice across the site, which reduced bounce rate. Combine this with AI writing benchmarks for 2026 to calibrate against industry baselines.
Prioritize the refresh by traffic, not by date. The top 50 posts by traffic carry 70% of reader impressions in most archives. Updating these moves the brand perception faster than updating an evenly distributed sample. Use Google Search Console to pull the traffic ranking. Sort descending. Start at the top.
Track each refreshed article in a spreadsheet. URL, original publish date, refresh date, voice score before, voice score after. The data lets you prove the refresh worked when stakeholders ask whether the work was worth it.
Step 8: Run a Quarterly Voice Calibration Review With Stakeholders
The voice spec is not a static document. It evolves with the brand. Quarterly calibration reviews with stakeholders prevent the voice from drifting away from how the leadership team actually wants the brand to sound. The review is also where new product launches, new market entries, and new stance positions enter the spec officially.
The agenda is 60 minutes. Review the drift detection scores from the quarter. Review any voice issues flagged by editors or readers. Review any new vocabulary or stance positions that need formal documentation. Decide on any spec updates. Schedule the refresh sprint if updates are significant.
A 2026 Forrester report on content operations found that brands running quarterly voice calibration reviews published 2.3x more content per year than brands that updated voice docs ad hoc. The mechanism is rhythm. A predictable cadence prevents emergency updates that disrupt the production pipeline.
The right stakeholders are the head of content, the head of marketing, the founder if the brand voice is founder-anchored, and one senior editor who runs the daily audit. Larger groups produce slower decisions. Smaller groups miss important perspectives. Four people works.
Document every decision in a changelog appended to the voice spec. Date, decision, rationale, downstream actions. The changelog becomes the institutional memory of how the voice has evolved. Future stakeholders can understand why current rules exist. Future audits can reference the historical context.
Stacc runs this review on the third Thursday of every quarter for every retained client. The cadence is non-negotiable. Brands that skip the review tend to drift. Brands that hold the review tend to compound.
Step 9: Treat Voice Engineering as a Discipline, Not a Project
The final step is the cultural one. Voice engineering is a discipline that runs forever. It is not a project that ends. The teams that succeed treat it as ongoing infrastructure work. The teams that fail treat it as a one-time setup and then walk away.
The discipline has three components. A documented voice spec that gets updated quarterly. A prompt template library that gets audited monthly. A pre-publication voice audit that runs on every article. Drop any of the three and the system degrades. Hold all three and the system compounds for years.
The output of the discipline is a brand that scales without losing its voice. The compounding effect is significant. After 18 months of disciplined voice engineering, brands typically publish 3 to 5 times the content volume of pre-AI baseline while holding voice consistency scores above the original human-only baseline. The math works because voice engineering removes the bottleneck that limited human-only content operations.
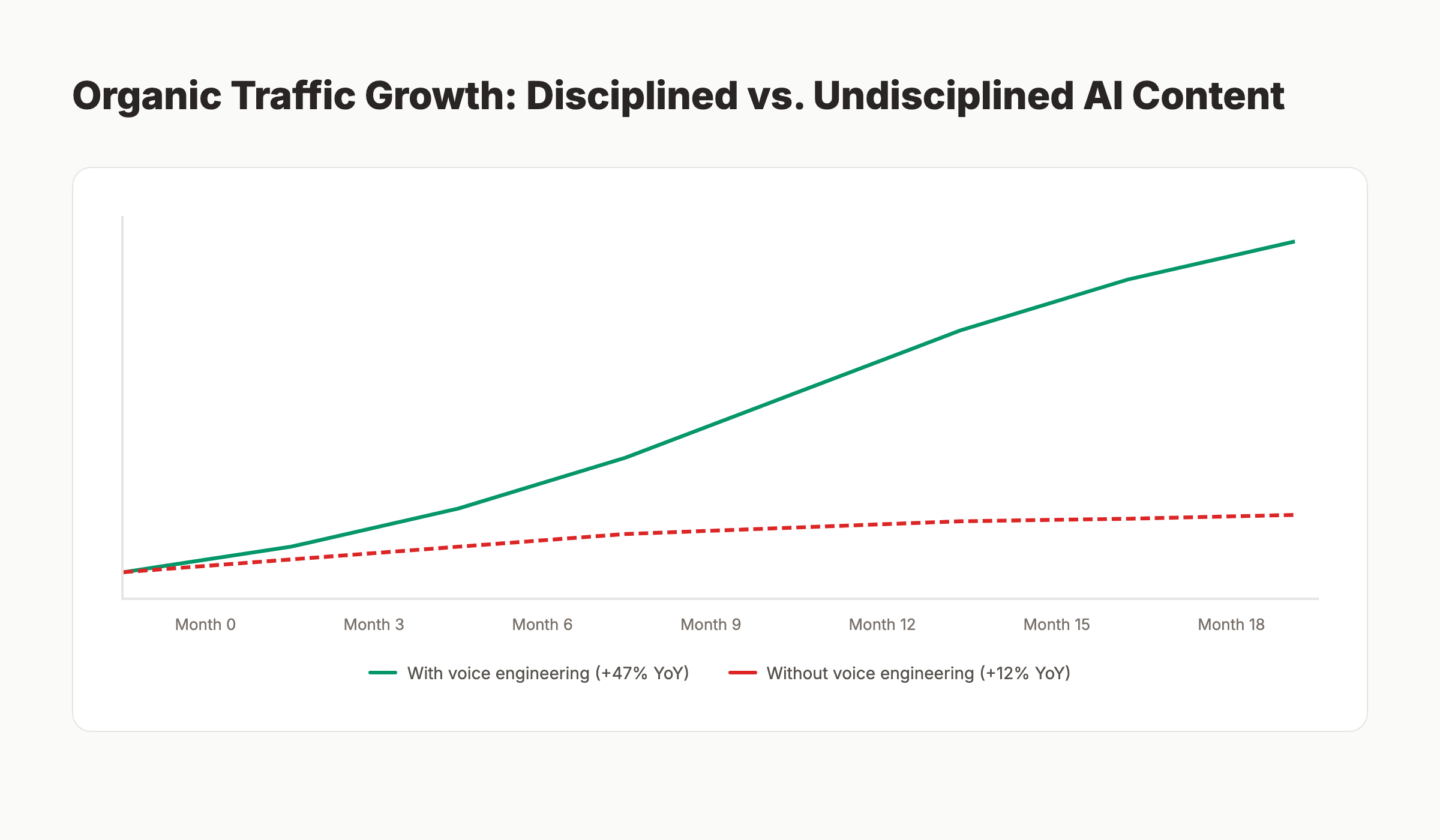
According to a 2026 Gartner report on AI content operations, brands with mature voice engineering practices grew organic traffic at a median rate of 47% year over year. Brands using AI without voice engineering grew at 12% year over year. The 35-point gap is the value of the discipline.
The brands that fall behind are the ones that adopted AI quickly but did not adopt voice engineering. They published faster. They lost their voice. Readers stopped recognizing the brand. Engagement metrics dropped. Organic traffic plateaued even as content output increased. Voice engineering is the missing layer that lets AI content scale without breaking the brand.
The work is procedural. The procedures are documentable. The documentation is reusable. None of this requires special talent. It requires discipline, which is the rarer asset.
Common Mistakes That Derail AI Brand Voice Training
The same mistakes appear in nearly every brand voice failure we audit. The list below covers the patterns we see most often and how to avoid each one.
- ✓ Defining voice with adjectives instead of behavioral rules. "Friendly and expert" produces 50 different outputs. Replace with sentence length rules, banned word lists, and paired examples.
- ✓ Writing the voice doc once and never referencing it in prompts. The doc must be embedded in every generation prompt, not stored in a Notion page that nobody opens.
- ✓ Using one prompt template across multiple models. ChatGPT, Claude, and Gemini drift in different directions. Calibrate per model with tool-specific instructions.
- ✓ Skipping the pre-publication audit because facts get checked. Facts and voice are different. Add the voice audit as a separate step before any article ships.
- ✓ Ignoring drift detection until readers complain. Quarterly audits catch drift at month 3. Reader complaints catch drift at month 12. The math favors early detection.
- ✓ Refreshing old content without updating the voice spec. The opposite mistake is also common. Update one without the other and the system breaks.
- ✓ Running voice training as a one-time project. The discipline runs forever. Brands that treat it as a sprint always regress within 6 months.
- ✓ Letting writers improvise voice instructions into prompts. Improvisation is the source of drift. Lock the templates. Changes go through review.
- ✓ Skipping the stakeholder review because the team is busy. The 60-minute quarterly review prevents 60 hours of cleanup work later.
Each of these mistakes is preventable with the 9-step method above. The method is procedural. The procedures compound. Start with step 1 and work in order. Do not skip to step 5 because audit feels concrete. The earlier steps create the inputs that make step 5 possible.
Results: What to Expect From Disciplined Voice Engineering
Brands that complete the 9-step method typically see measurable changes within 90 days. Voice consistency scores rise from a typical baseline of 50 to 65 percent to a sustained range of 85 to 92 percent. Reader engagement metrics improve modestly, with average time on page increasing 15 to 25 percent. Branded search volume tends to grow 8 to 15 percent over 6 months as brand recognition strengthens.
The compounding effects take longer to appear. Organic traffic growth typically accelerates after month 6 as Google's quality raters and ranking systems detect the consistency improvements. By month 12, brands running the discipline tend to publish 3 to 5 times the volume of their pre-AI baseline while maintaining or improving voice consistency scores. The volume increase produces topical authority gains that compound through year 2.
Set expectations correctly. The 9-step method is a discipline, not a quick win. The first 30 days produce diagnostic value. The first 90 days produce measurable consistency improvements. The first 12 months produce traffic and brand recognition compounding. Brands that abandon the work in month 3 because results feel slow miss the compounding window entirely.
Get a documented voice that scales with AI without the engineering work. Stacc handles the audit, voice spec, prompt templates, and quarterly drift detection so you can publish 30 articles a month with one consistent brand voice. No setup fees. 14-day free trial.
What practitioners are saying on X
AI search advice ages quickly. Here is high-signal public discussion from SEO and growth operators — context for your roadmap, not a substitute for primary data.
- @jakezward (Feb 2026): 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers as a KPI, proprietary data as a moat, and content refresh beating net-new AI slop. See the post on X.
- @alexgroberman (Jul 2026): Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category authority links, commercial intent content, and tight internal linking — not thin product copy. See the post on X.
- @varunram (Jul 2026): Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research still separate winners from farms. See the post on X.
Grok, AI Overviews, and multi-engine visibility
AI/search topics like “train ai agent brand voice” need multi-engine notes: AI Overviews, ChatGPT/Perplexity, and Grok. Lead with extractable answers; keep claims consistent with public expert discussion.
- Google AI Overviews: Use passage-ready answers, tables, and FAQ schema where relevant.
- ChatGPT / Perplexity: Cite named sources next to key claims.
- Grok: Maintain accurate entity facts on-site and in high-signal X posts.
Frequently Asked Questions
A complete voice training cycle takes 4 to 6 weeks for a typical brand. Week 1 covers the voice audit and baseline scoring. Weeks 2 and 3 cover the voice spec creation. Week 4 covers prompt template development and tool-specific calibration. Weeks 5 and 6 cover initial production runs with audit refinement. After the initial cycle, ongoing maintenance runs 4 hours per month for the quarterly cadence.
Yes, but you cannot use the same prompt for both. ChatGPT and Claude interpret voice instructions differently. Use the same underlying voice spec, then create tool-specific prompt templates that add corrective instructions per model. Calibration per model closes the gap that single-prompt approaches leave open. The Allen Institute for AI study cited above showed convergence to 87 to 89 percent consistency across models with calibration.
Brand voice is the consistent identity across all communications. Tone of voice adjusts within that identity based on context. For AI training, the voice spec defines the consistent rules. Context-specific instructions in the prompt adjust the tone. A blog post and a sales email use the same voice but different tones. The voice rules stay constant. The tone rules vary by content type.
Score each article on a 15-item checklist covering sentence length distribution, banned word counts, banned phrase counts, brand name frequency, stance alignment, opening hook type, and CTA format. Weight the items based on what matters most for your brand. A score of 85 or higher indicates strong consistency. A score below 75 indicates the article needs rework. Track scores over time to detect drift.
Three causes produce most voice drift. First, prompt templates get edited ad hoc without testing, which shifts the voice baseline. Second, model versions update and behavior changes without recalibration. Third, writers improvise voice instructions into prompts instead of using locked templates. Address all three and drift stays under control. Address one and drift continues.
Google does not penalize AI content specifically. Google penalizes low-quality content. Inconsistent voice across a domain is a quality signal that the 2026 Search Quality Rater Guidelines explicitly flag. Sites with inconsistent voice score lower on "consistent expertise signals across a domain." The penalty is indirect but real. Consistent voice is a quality signal regardless of whether the content was written by humans or AI.
Yes, but the scope adjusts to volume. Small businesses publishing 4 to 8 articles a month can use a lighter version of the method. A 4-page voice spec instead of 12 pages. A simplified audit checklist with 8 items instead of 15. Quarterly reviews via async document instead of meetings. The discipline matters more than the formality. Brands publishing any AI content benefit from voice engineering.
The Bottom Line
Training AI on brand voice is not a creative exercise. It is an engineering discipline. The teams that succeed treat voice as structured input, not subjective interpretation. The teams that fail treat voice as adjectives and hope. The difference shows up in consistency scores within 90 days and in organic traffic within 12 months.
Three things to take away from this guide:
- Voice engineering is procedural. The 9-step method works because it removes guesswork at every layer from voice spec through audit through drift detection.
- The audit step is the enforcement layer. Without it, voice documents become aspirational paperwork. With it, voice becomes operational.
- The discipline compounds. Brands that hold the cadence for 12 months tend to publish 3 to 5 times their pre-AI baseline volume with stronger voice consistency than the human-only era.
Brands that train AI on brand voice now will compound their content advantage through 2026 and beyond. Brands that publish AI content without voice engineering will accumulate inconsistencies that drag down rankings and brand recognition.
Skip the engineering work and get the results. Stacc publishes 30 articles a month with one consistent brand voice across multiple models, audited and maintained by our team. Starting at $99/month with a 14-day Try for free. Start your trial →
Related Tools & Resources
Free SEO Tools:
Best Lists:
Sources & references
- [1] Princeton / Georgia Tech et al. — GEO research (arXiv:2311.09735)
- [2] @jakezward on X — 2026 SEO predictions emphasize AI Overview share-of-SERP, schema for LLM token efficiency, brand mentions in AI answers
- [3] @alexgroberman on X — Case narrative: organic value plus multi-engine citations (ChatGPT, Perplexity, Grok) from knowledge-hub pages, category
- [4] @varunram on X — Critique of GEO slopfarm products that combine SEO clickbait with unresearched content marketing — quality and research

Researched, written, and published articles that compound organic traffic.
Weekly local SEO teardowns
One practical email a week. Map Pack, GBP, AI Overviews — no fluff. Unsubscribe anytime.